지난 회 차에 여러 가지 문제로 .NET 스마트클라이언트가 가진 문제점을 살펴 보았습니다. 그 중, 주된 이슈는 이미 로드된 어셈블리는 업데이트/갱신이 불가능하다는 것과, 메모리의 사용률이 지속적으로 증가한다는 문제입니다. 이러한 문제는 사내 정책적인 서버를 도입하여 해결 가능하지만, 대부분의 조직과 기업은 이러한 정책 서버를 도입하지 않는 것으로 알고 있습니다.
이미 얘기 했다시피, 평소에도 .NET 에서 이러한 문제를 가지고 고민을 했었지만, 최근 이러한 문제가 이슈가 되었을 때 더 이상 필자 또한 방관할 수 없었습니다. 왜냐하면 "안된다!" 라는 것 자체가 .NET 의 많은 매리트를 배제한다는 의미가 될 수 있기 때문입니다. 이러한 문제로 '목숨거는' 고객이라면 차라리 '지금은 곤란하다. 조금만 기다려달라' 라는 답이 훨씬 나아 보입니다. 물론 이런 문제가 가능하다는 전제 조건으로 말입니다.
문제 해결 방안
일단, 몇 날 몇 일을 고민하며 생각한 끝에 아래와 같은 아키텍처링을 하게 되었습니다. 물론 최선의 방법도, 최적의 방법도 아니지만, 문제가 된다면 저에게 피드백을 주시기 바랍니다. 저 또한 짧은 지식으로 이러한 고민을 하게 되었으니 저도 많이 답답하네요^^;
위의 아키텍처링은 논리적인 아키텍처입니다. 이 방법을 통해 이전 아티클을 통해 골치 아픈 .NET 어플리케이션의 메모리 릭(Memory Leak) 을 해결할 수 있을 것으로 기대합니다.
어플리케이션과 AppDomain 의 분리
.NET 어플리케이션은 기본적으로 하나의 프로세스(Process) 를 차지하게 됩니다. 그것이 독립 프로세스든, IEHost.DLL 또는 IEExec.EXE 든 간에 말이죠. 이 독립 프로세스는 독립적인 하나의 어셈블리에서 관장하게 됩니다. 기본적인 이 부분의 컨셉은 어플리케이션의 재시작을 방지하기 위한 방법이기도 합니다.
기존의 어플리케이션의 프로세스와 AppDomain 을 분리함으로써 최소한으로 AppDomain 이 안전하게 언로드될 수 있는 환경을 제공하는 것입니다. 그리고 위해 AppDomain Manager 는 이것을 관장하는 최상위 Manager Layer 가 됩니다.
MVVM 으로 구현부와의 분리
MVVM(Model View ViewModel) 패턴의 가장 큰 특징은 View 와 ViewModel 을 분리한 것입니다. 이것을 분리함으로써 View 와 ViewModel 의 종속 관계를 완전히 해결하고, ViewModel 은 격리된 AppDomain 으로 제한함으로써 언제든지 AppDomain 이 언로드될 수 있게 합니다.
이 부분을 구현하기 가장 이상적인 환경은 바로 WPF(Windows Presentation Foundation) 이 되겠네요.
Views 의 교체
MVVM 으로 구현부와의 분리를 통해 당연히 Views 는 언제든지 교체가 가능합니다. 서버/로컬에서 Views 가 교체된다면 ViewModels 을 언로드하고 새로운 Isolated AppDomain 을 생성하여 View 와 ViewModel 간에 연결하는 방법입니다.
특히 이 통신 구간은 View 와 ViewModel 간의 Interface Contract 를 통해 크리티컬한 자원의 관리를 최소화하는 것에 있습니다. 이로써 이미 로드된 사용자 화면과 어셈블리라도 서버/로컬의 갱신이 있다면 언제든지 갈아치울 수 있는 구간입니다. 이 부분이 앞서 얘기한 .NET 스마트클라이언트의 문제를 해결할 수 있는 핵심 구간입니다.
업데이트 기능을 재작성
이 아키텍처링의 가장 큰 문제지만, .NET 스마트클라이언트의 NTD(No Touch Deployment) 기능을 그대로 사용할 수 없습니다. .NET 의 NTD 는 이미 실행되는 AppDomain 에 어셈블리를 로드하기 때문에 .NET 의 NTD 를 그대로 사용한다면 이 아키텍처링을 적용할 수 없습니다.
NTD 기능 뿐만 아니라, ClickOnce 의 자동 버전 감지 기능도 사용할 수 없습니다. ClickOnce 는 주기적으로 서버의 Application Manifest 를 확인하는 과정으로 새로운 버전을 감지하고 업데이트하는데, 이 기능을 그대로 사용한다면 위의 아키텍처링은 사실상 무의미하고, 결국 메모리 사용 증가는 해결할 수 없기도 합니다.
제한 사항
하지만 필자가 제안한 .NET 스마트클라이언트의 문제를 해결하기 위한 방법은 제한적인 방법으로 수행이 가능합니다. 물론 모든 경우라도 제안이 가능한 방법이라면 좋겠지만, .NET 의 기본 아키텍처가 해결하지 못한 이상, 필자 또한 제한적인 방법으로 .NET 스마트클라이언트의 문제점을 해결할 수 있습니다.
그 제한적인 방법의 한계는 아래와 같습니다.
개발 표준을 완벽하게 MVVM 기반으로 개발되어야 한다.
MVVM 패턴으로 완벽하게 분리가 되어야 한다.
WPF 를 사용할 경우 MVVM 패턴으로만 작성되어야 한다.
윈도우 폼(Windows Forms) 또는 ActiveX 컨트롤 일 경우, MVVM 로 작성할 수 없다.
이 경우, View와 ViewModels 를 분리하도록 별도 프레임워크 개발이 필요하다.
Marshaling 을 통한 통신
Marshaling 은 AppDomain 간의 원격 통신을 해야 한다.
원격 통신으로 인한 성능 저하
WPF 개발
Binding Expression 을 확장한 Binding Marshaling Expression(단지, 예임) 으로 바인딩을 해야 한다.
원격 바인딩으로 성능 저하 예상
결론
필자는 .NET 어플리케이션이 업데이트될 경우 왜 반드시 최적의 방법이 어플리케이션 쉘을 재시작하느냐에 시작한 고민으로부터 시작됩니다. .NET 아키텍처를 이해못하는 것은 아니지만, 고객은 언제나 더 향상된 방법을 제안합니다. 그리고 필자는 그런 고민을 극복하고자 제안한 방법입니다.
물론 위의 아키텍처링을 효율적인 면과 성능적인 면을 더 자세히 테스트해 보아야 하겠지만, 분명한 것은 끊임없이 고객의 요청은 진화하지 퇴화하지는 않을 거라고 생각합니다.
예전에 필자는 위와 같은 문제를 문의할 때, ".NET 에서는 안된다" 라고 답했습니다. 맞아요. 안됩니다. 하지만 문득, '안되면 되게 해야지!' 라는 생각이 들더군요. 짧은 소견이지만 잘못된 부분이 있으면 언제든지 피드백 주시기 바랍니다.
.NET 에서 윈도우 어플리케이션을 개발해 본 독자라면 한번 쯤은 .NET 스마트클라이언트라는 용어를 많이 들어보았을 것입니다. 스마트클라이언트는 배포(Deployment), 플랫폼 독립 모델을 제공함으로써 다양한 클라이언트를 지원하는 것이 특징입니다.
예전에 필자가 UX 라는 주제로 쓴 포스트 중 "당신이 생각하는 UX 란?" 에서도 언급하였듯이, .NET 스마트클라이언트는 X-Internet 이라는 트랜드로 기술적인 부분을 초점으로 마케팅한 용어로 발전하였습니다. 이와 반대로 RIA(Rich Internet Application) 는 UX(User eXperience) 초점에서 마케팅한 용어라고 보셔도 좋습니다.
사전 지식
하지만 .NET 스마트클라이언트는 사실상 매번 나오는 이슈가 있습니다. 아니, 이것은 .NET 스마트클라이언트의 문제라기 보다는 .NET 자체의 아키텍처와 관련된 문제이기도 합니다.
결혼부터 말하자면, .NET 어플리케이션은 로드된 어셈블리(Loaded Assemblies) 는 언로드(Unload) 가 되지 않습니다. 간단하게 아래와 같이 .NET 어플리케이션의 모델을 보면 알 수 있습니다. .NET 어플리케이션은 하나의 AppDomain(Application Domain) 을 갖는 것을 알 수 있습니다.
AppDomain 은 어플리케이션 간의 CAS(Code Access Security) 라는 임계 영역에 존재하게 됩니다. 말 그대로 CAS(Code Access Security) 이 CAS는 어플리케이션간의 엑세스를 제한함으로써 신뢰할 수 없는 코드나 어플리케이션은 사용자의 컴퓨터에서 실행할 수 없도록 한 보안 모델입니다.
즉, 이메일이나 인터넷, 사용자 그룹 및 권한 등 신원이 확인되지 않은 어플리케이션을 실행했을 때, 악의적인 목적으로 사용자의 로컬 자원을 엑세스할 수 없도록 제한하는 모델이라고 보시면 됩니다.
이 코드 보안 모델은 .NET 의 어떤 어플리케이션이든 모두 이 보안 정책 안에 있다고 보시면 됩니다. ASP.NET 도 마찬가지로 아래와 같이 AppDomain 의 임계 영역 안에서 어플리케이션이 동작하게 됩니다. AppDomain 이 하나의 웹 어플리케이션을 동작하게 하고, HttpRuntime 에 의해 HttpContext 가 관리됩니다. 그리고 각각의 요청에 의해 HttpContext 는 별도의 스레드(Thread) 로 사용자의 요청을 응답하게 되는 구조라고 보시면 됩니다.
예를 들어, 아래와 같은 코드 보안을 위한 선언적인 방법을 이용하여 악의적으로 사용될 수 있는 코드 쓰기, 수정 등을 할 수 없도록 합니다. 어셈블리, 클래스, 구조체, 생성자에서 사용할 수 있습니다. 물론 사용자가 이 보안 수준을 변경할 수 도 있지요.
문제 1
여태까지 이것을 말하기 위해 설명을 한 것입니다. 바로 .NET 어플리케이션은 어셈블리를 로드할 수 는 있지만, 언로드할 수 는 없습니다.
그러니까 더 자세하게 얘기하면, 아무리 가비지 컬렉션(Garbage Collection) 을 호출하고 CLR Runtime(Common Language Runtime) 이 이것을 대신 수행해 준다고 해도, 로드된 어셈블리 자체는 이 대상에서 예외라는 것입니다. 결론은 .NET 어플리케이션을 오래 쓰면 쓸 수록 메모리 사용이 증가할 가능성이 있습니다.
플러그인 모델(Plugin Model) 기반의 어플리케이션도 확장 기능이 많아지면 많아질 수록 메모리 점유율이 높아지고, 특히 엔터프라이즈 기업용 어플리케이션은 반드시 피해갈 수 없는 문제이기도 합니다.
개인적으로 플러그인 모델과 엔터프라이즈 어플리케이션의 중간 영역이라고 생각되는 Visual Studio 를 한 1주일 정도 닫지 않고 써보셨나요? 쓰지 못할 정도는 아니지만, 괜히 버벅되고 느려지는 현상이 나타나게 된답니다.^^; 이런 현상은 Visual Studio 뿐만이 아니라 .NET 으로 작성된 모든 어플리케이션은 모두 영향을 받게 됩니다.
그 이유는, .NET 은 로드된 AppDomain 의 어셈블리를 언로드할 수 있는 방법을 제공해 주지 않습니다. AppDomain 이 참조하는 관계는 기본적으로 로컬 자원의 어셈블리를 참조하겠지만, 코드 베이스(Code Base-코드의 출처) 가 인트라넷이나 인터넷이라면 그 코드 베이스로부터 어셈블리를 다운로드 하게 됩니다.
문제 2
결론부터 말하면, .NET 어플리케이션은 참조 또는 다운로드한 어셈블리는 다운로드 캐시(Download Cache) 에 보관하게 됩니다. 어셈블리를 참조 또는 다운로드하는 판정 조건은 어셈블리의 버전, 토큰 등 복잡한 과정을 거치기 때문에, 제대로 된 정책을 갖고 있지 않는다면, 이미 다운로드된 어셈블리는 다운로드 캐시로부터 어셈블리를 재사용합니다.
그렇기 때문에, 다운로드된 어셈블리는 File Lock(파일 잠김)이 발생하므로, 동일한 파일 이름의 어셈블리를 다운로드 받는 것은 불가능 합니다. 하지만 해결책이 없는 것은 아닙니다. Assembly.Load 시리즈의 메서드에는 byte[] 로 읽을 수 있는 오버로드된 메서드가 존재하기 때문입니다.
즉, 아래와 같이 File Lock 을 방지할 수 있습니다. 하지만 어셈블리는 로드할 수 있으나, 기존의 로드된 어셈블리를 갈아치우지는 못합니다.
결국, 하나의 어플리케이션을 오래 사용하면 할수록 메모리의 점유율을 증가할 수 있게 될 가능성이 큽니다. 특히 엔터프라이즈 기업용 어플리케이션은 단위 업무별로 적절한 파일 크기, 업무간의 연간 관계 등을 고려하여 어셈블리를 모듈화하는데, 사실상 메모리 사용률 증가의 문제는 여전히 해결할 수 없는 문제입니다. 그 이유는, 앞서 말했듯이 어셈블리를 언로드할 수 있는 방법은 AppDomain 을 언로드하는 것이고, AppDomain 을 언로드하면 메인 어플리케이션을 재시작해야 된다는 문제입니다.
문제 3
이 섹션은 문제 2와 연관된 정책적인 문제입니다. 다운로드된 어셈블리는 다시 다운로드 받을 수 없기 때문에 선행적으로 몇 가지 정책적인 강제가 필요할 수 밖에 없습니다.
어플리케이션 쉘(Shell)
어플리케이션 쉘이 업데이트되면 어플리케이션을 재시작 해야 한다.
어플리케이션 실행 중 단위 어셈블리
단위 어셈블리가 한 번 다운로드되면 서버/로컬의 어셈블리가 갱신되도 다운로드 받지 못한다.
단위 어셈블리가 다운로드 되고 서버/로컬 어셈블리가 갱신되어도 알림 받을 수 없다.
이럴 경우, 어플리케이션 쉘을 서버에서 갱신하여 업데이트 알림을 받을 수 있고, 어플리케이션을 재시작 해야한다.
즉, 어떠한 경우라도 갱신된 어플리케이션을 적용하기 위해서는 메인 어플리케이션 쉘을 재시작해야 한다는 결론을 얻을 수 있습니다.
이유의 요지는, IEHost.DLL 과 IEExec.EXE 파일이 .NET Framework 2.0 으로 강력한 이름의 서명이 되었다는 것입니다. 이것은 즉, IEHost.DLL 과 IEExec.EXE 를 통하는 .NET 스마트클라이언트의 경우 GAC(Global Assembly Cache) 를 통해 활성화가 되는데, .NET Framework 4.0 의 스마트클라이언트 어플리케이션은 어셈블리 리디렉트(Assembly Redirect)를 통하지 않고서는 이것을 활성화할 수 있는 방법이 없습니다. 어셈블리 리디렉트를 통한다고 하더라도 Dependency Assemblies 는 .NET Framework 2.0 을 바라보기 때문에 .NET Framework 4.0 의 기능을 사용한다면 절대 불가능하기도 합니다.
하지만 .NET 어셈블리의 바이트 코드 조작을 통해서 가능하긴 합니다.
IEHost.DLL, IEExec.exe 의 바이트 코드를 수정하여 강력한 서명을 지운다
IEHost.DLL, IEExec.exe 의 바이트 코드를 수정하여 .NET 4.0 으로 저장한다
GAC(Global Assembly Cache) 에서 IEHost.DLL 과 IEExec.EXE 를 제거한다.
어셈블리의 바이트 코드 조작은 Mono 프레임워크를 통해서 아주 쉽게 할 수 있습니다. 하지만 IEHost.DLL 과 IEExec.EXE 를 사용하는 모든 사용자 클라이언트를 해킹하는 무자비한 방법입니다. 하지만 된다는 것만으로도 만족한다면 이 방법이 최선의 방법이 될 것 같네요.
.NET 스마트클라이언트의 고찰
.NET 스마트클라이언트는 .NET 엔터프라이즈 어플리케이션에 많은 기여를 하였습니다. 그리고 .NET 스마트클라이언트를 사용하는 기업 또는 인트라넷 환경은 매우 많기도 합니다.
필자 또한 얼마 전에 이러한 고민으로 Microsoft 의 의뢰를 받은 적이 있습니다. 그리고 개인적으로 아주 많이 고민했습니다.
왜냐하면 자바의 클래스 로드(Class Loader) 는 .NET 의 스마트클라이언트와 유사한 점이 굉장히 많습니다. 하지만 다른 점이 하나 있다면, 자바의 클래스 로더는 GC(Garbage Collection) 의 대상이 된다는 것이죠. 다시 말하면, 어플리케이션의 재시작 없이 마음만 먹으면 메모리 사용률이 증가하지 않도록 아키텍처링이 가능하다는 것입니다.
필자가 결론적으로, .NET 의 AppDomain 과 자바의 클래스 로더는 각기 특색은 있지만, 어느 것이 정답인지는 모르겠습니다. 다만, 고객이 어플리케이션의 재시작 없이 어플리케이션 업데이트/갱신이 가능해야 한다는 전제 조건이라면 자바의 클래스 로더가 장점이긴 합니다.
하지만, 필자는 이 문제로 몇 일 동안 고민했습니다. 왜냐하면 세상에는 불가능한 것이 없다라는 것이 필자의 신념이기도 하며, 어떤 문제든 최선의 방법이라는 것이 존재한다고 믿습니다. 그리고 결국 "빙고" 를 찾았습니다. ^^
다음 회 차에서는 .NET 스마트클라이언트의 이러한 문제를 개선할 수 있는 방법을 알아보도록 하겠습니다.
DirectX11 을 통해서 가장 많은 관심을 가지고 있는 부분 중 하나인 테셀레이션( Tessellation )은
갑자기 등장한 새로운 기능이 아닙니다.
< DirectX9에서의 테셀레이션의 등장 >
DirectX9 이 처음 세상에 등장할 때, 아래와 같은 특징들을 나열했었습니다.
- 2-D support
blt, copy, fill operations, GDI dialogs
- Adaptive tessellation
- Displacement mapping
- Two-sided stencil operations
- Scissor test rect
- Vertex stream offset
- Asynchronous notifications
- VS / PS 2.0
Flow control, float pixels
- Multiple render targets
- Gamma correction
Adaptive tessellation 이 보이시죠?
저도 그냥 무심코 지났던 DirectX9 소개 자료에서 우연히 찾았습니다.^^
< Adaptive tessellation >
테셀레이션에는 몇 가지 방법이 있는데,
그 중에 가장 유명한 것이 Adaptive 형식과 Uniform 형식입니다.
아래의 이미지를 보시기 바랍니다.
< 이미지 출처 : GPU Gems 2권 >
좌측의 경우가 Adaptive 한 방식입니다. Adaptive 한 방식을 간단히 설명드리면,
시점의 위치에 근거에서 얼마나 많은 면을 생성할 지를 판단해서,
테셀레이션 작업을 하는 것입니다.
반면에 Uniform 한 방식은,
모두 균일한 면의 갯수로 테셀레이션 작업을 수행하는 방법입니다.
Uniform 한 방식이 더 연산 수가 많은 것이 일반적이기 때문에,
Adaptive 한 방식이 게임 분야에서 주로 사용됩니다.
< 테셀레이션을 위해 필요한 정보 >
테셀레이션 작업을 위해서는 두 가지가 필요합니다.
그것은 제어점들( Control Points )과 테셀레이션 팩터들( Tessellation Factors ) 입니다.
제어점들은 파이프라인에 입력으로 들어감으로써 패치( Patch ) 형태로 변환되어서
최종적으로 렌더링되게 됩니다.
이 과정에 대한 자세한 설명은 앞으로도 꾸준히 언급될 것입니다.
지금은 간단하게 이 정도로만 설명하고 넘어가겠습니다.^^
< ID3DXPatchMesh >
그러면 DirectX9 은 어떤 방식으로 테셀레이션 작업을 지원했을까요?
그것은 ID3DXPatchMesh 라는 인터페이스를 통해서 간접적으로 지원했습니다.
참고적으로 얘기드리면, DirectX 에서는 D3DX 라는 유틸리티를 통해서
메시를 관리할 수 있는 클래스를 제공했습니다.
ID3DXBaseMesh, ID3DXMesh, ID3DXSPMesh, ID3DXPMesh,
그리고 마지막으로 언급드렸던 ID3DXPatchMesh 입니다.
ID3DXPatchMesh 인터페이스는 다른 메시들을 지원하는 클래스와 다릅니다.
일반적인 메시 인터페이스들은 ID3DXBaseMesh와 계층 관계를 이루는 반면에,
ID3DXPatchMesh 는 완전히 별도로 구성된 클래스입니다.
즉, ID3DXPatchMesh 클래스는 IUnknown 인테페이스를 상속받습니다.
ID3DXPatchMesh는 테셀레이션 작업을 위해서 각종 멤버 함수를 가지고 있습니다.
실제로 테셀레이션 작업을 하는 함수는 ID3DXPatchMesh::Tessellate() 와
ID3DXPatchMesh::TessellateAdaptive() 입니다.
이들 함수에 대한 형태는 다음과 같습니다.
이들에 대한 모든 작업은 CPU 가 담당합니다.
또한 연산량도 많기 때문에 Adaptive Tessellation을 처리하기는 상당한 무리가 있습니다.
왜냐하면 Adaptive Tessellation은 시점에 근거해서 매번 폴리곤을 생성해야하기 때문입니다.
ID3DXPatchMesh::Optimize() 라는 최적화 함수를 미리 호출해 줄수도 있지만,
그래도 이는 분명 매우 부담스러운 연산입니다.
< 마치면서... >
이상으로 ID3DXPatchMesh 를 활용한 DirectX9 의 테셀레이션 작업에 대해서 살펴보았습니다.
DirectX9 에서의 테셀레이션 작업의 불편함과 성능 문제를 이해한다면,
DirectX11 에서의 테셀레이션 작업의 우수성을 알 수 있을 것이라 생각됩니다.
다음 시간에도 계속 DirectX9 에서의 테셀레이션 작업에 대해서 살펴보겠습니다.^^
이전 글에서 message block 의 인터페이스인 ISource 와 ITarget 인터페이스에 대해서 알아보았습니다. 이번 글부터 그 인터페이스들을 상속받아 구현한 message block 에 대해 알아보겠습니다.
Message block 은 버퍼( buffer ) 를 가질 수도 있고, 상태만 가질 수도 있고, 기능만 가질 수도 있습니다. 그러므로 각 message block 들의 특징을 잘 파악하고, 언제 필요한지 알아야 합니다.
이번 글에서는 가장 범용적인 유용한 unbounded_buffer 에 대해서 알아보도록 하겠습니다.
unbounded_buffer< _Type >
unbounded_buffer 는 message block 중 가장 많이 사용될 것입니다. unbounded_buffer 는 내부적으로 큐( queue )를 구현하고 있어 message 저장소 역할을 합니다. 누군가 unbounded_buffer 에 message 를 보내면 unbounded_buffer 에 순서대로 차곡차곡 쌓이고, 쌓인 순서대로 꺼내서 쓸 수 있습니다. 꺼낸 message 는 unbounded_buffer 에서 제거됩니다. 그렇기 때문에 여러 곳에서 같은 message 를 꺼내 받을 수 없습니다.
이런 작업들은 비 동기 agent 들과 사용할 때, 빛을 발합니다.
unbounded_buffer 는 스레드에 안전하므로 직접 lock 을 하지 않아도 됩니다.
생성자
unbounded_buffer() – 기본 생성자
빈 unbounded_buffer 를 생성합니다.
unbounded_buffer( filter_method const& _Filter )
빈 unbounded_buffer 를 생성합니다. 하지만 필터 함수를 지정하여 받을 수 있는 메시지를 거를 수 있습니다.
이 필터 함수는 bool (_Type const &) 형의 시그니처( signature )를 갖습니다.
멤버 함수
bool enqueue( _Type const& _Item )
하나의 message 를 unbounded_buffer 에 보냅니다.
message 전송이 성공이면 true, 아니면 false 를 반환합니다.
내부적으로 이 함수는 message 전달 함수인 send() 를 사용합니다. 그리고 send() 의 결과를 반환합니다.
_Type dequeue()
unbounded_buffer 에서 하나의 message 를 꺼냅니다. 꺼낸 message 는 큐에서 제거됩니다.
꺼내진 message 를 반환합니다. 그리고 꺼내진 message 는 unbounded_buffer 내부에서 제거됩니다.
enqueue() 와 마찬가지로 내부적으로 message 전달 함수인 receive() 를 사용합니다. receive() 가 반환한 값을 반환합니다.
예제
unbounded_buffer 를 사용하여 작은 시나리오를 구현해보도록 하겠습니다.
시나리오
윈도우즈 OS 는 사용자의 이벤트들을 메시지 큐에 담고, 큐에 들어온 메시지들을 순차적으로 꺼내서 처리하는 메커니즘을 사용합니다. 이 시나리오를 agent 와 unbounded_buffer 를 이용하여 간단하게 구현해보겠습니다.
코드
#include <iostream>
#include <string>
#include <agents.h>
using namespace std;
using namespace Concurrency;
// 메시지 객체
class Message
{
wstring message;
public:
Message( const wstring& message )
: message( message ) { }
const wstring& GetMessage() const
{
return this->message;
}
};
// 메시지를 발생하는 사용자 agent
class User
: public agent
{
ITarget< Message >& messageQueue;
public:
User( ITarget< Message >& target )
: messageQueue( target ) { }
void ClickMouseLButton()
{
send( this->messageQueue, Message( L"WM_LBUTTONDOWN" ) );
send( this->messageQueue, Message( L"WM_LBUTTONUP" ) );
}
void DragMouseLButton()
{
send( this->messageQueue, Message( L"WM_LBUTTONDOWN" ) );
send( this->messageQueue, Message( L"WM_MOUSEMOVE" ) );
send( this->messageQueue, Message( L"WM_LBUTTONUP" ) );
}
virtual void run()
{
this->ClickMouseLButton();
Concurrency::wait( 1000 );
this->DragMouseLButton();
this->done();
}
};
// 발생한 메시지들을 처리하는 메시지 펌프 agent
class MessagePump
: public agent
{
ISource< Message >& messageQueue;
public:
MessagePump( ISource< Message >& source )
: messageQueue( source ) { }
void ProcessMessage( const Message& message )
{
wcout << message.GetMessage() << endl;
}
virtual void run()
{
while( true )
{
Message message = receive( this->messageQueue );
this->ProcessMessage( message );
}
this->done();
}
};
int main()
{
// 메시지 큐
unbounded_buffer< Message > messageQueue;
// 메시지를 발생하는 사용자와 메시지 펌프
User user( messageQueue );
MessagePump messagePump( messageQueue );
// agent 시작.
user.start();
messagePump.start();
// agent 의 작업이 모두 끝날 때까지 대기
agent* agents[] = { &user, &messagePump };
agent::wait_for_all( 2, agents );
}
[ 코드1. agent 와 unbounded_buffer 를 이용한 메시지 펌프 간략 구현 ]
Message 클래스는 단순히 문자열을 래핑( wrapping ) 하는 클래스로 큐에 저장되는 메시지를 나타냅니다.
agent 로 2개를 정의하였는데 하나는 사용자가 이벤트 메시지를 발생하는 것을 흉내 낸 User 클래스이고, 다른 하나는 메시지 펌프를 간략화한 MessagePump 클래스입니다.
사용자 agent( User 객체 )는 약간의 시간차를 두고 이벤트 메시지를 발생합니다. 발생된 메시지는 메시지 큐에 저장됩니다.
메시지 펌프 agent 는 메시지가 저장될 때까지 대기하다가 메시지가 저장되면 그 메시지를 받아서 처리합니다. 처리된 메시지는 메시지 큐에서 제거됩니다.
agent 들의 start() 를 사용하여 작업을 시작하고, 모든 agent 의 작업이 끝날 때까지 기다립니다.
실제로는 하나의 agent 가 무한 루프를 수행하므로 프로그램이 종료되지 않습니다.
위의 예제처럼 데이터를 보내고, 순차적으로 받아서 처리하고 싶을 때, 내부적으로 큐가 필요할 때 유용한 message block 이 바로 unbounded_ buffer 입니다.
멀티 스레드 프로그래밍 시 자료 구조 중 큐가 많이 사용되기 때문에 unbounded_buffer 도 많이 사용하게 될 것입니다.
[ 그림1. agent 와 unbounded_buffer 를 이용한 메시지 펌프 간략 구현 결과 ]
마치는 글
이번 글에서는 message block 중 가장 사용도가 높은 unbounded_buffer 에 대해서 알아보았습니다. unbounded_buffer 이외에도 다양한 message block 이 있습니다.
다음 글에서는 overwrite_buffer 라는 message block 에 대해서 알아보도록 하겠습니다.
setlocale로 국가를 설정하고(직접 나라를 지정할 수도 있고, 아니면 위처럼 시스템 설정에 따라가도록 할 수도 있습니다), ‘cout’ 대신
‘wcout’를 사용합니다.
관리코드 문자열과 비관리코드 문자열간의 변환에
따른 성능
C++로 만드는 프로그램은 보통 고성능을 원하는 프로그램이므로 보통 C++ 프로그래머는 성능에 민감합니다. 마샬링은 공짜가 아닙니다만
많은 양을 아주 빈번하게 마샬링 하는 것이 아니면 성능에 너무 신경 쓰지 않아도 됩니다. 다만 기본적으로
관리코드의 문자열은 유니코드입니다. 그래서 비관리코드의 문자열이
ANSI 코드라면 유니코드를 사용했을 때 보다 더 많은 시간이 걸립니다(정확한 수치는 잘
모르지만 ANSI가 유니코드보다 3배정도 더 걸린다고도 합니다). 그래서 관리코드와 비관리코드를 같이 사용할 때는 가능한 유니코드를 사용하는 것이 훨씬 좋습니다.
지난 7월 2일경 스캇구스리 옹의 블로그에서는 Razor 라는 새로운 view 엔진이 소개되었습니다. Razor 는 기존에 <%%> 으로 통칭되던 코드 블록을 좀더 간소화 시키기 위해 고안되었으며 , 스파케티 코드의 늪에서 허덕이는 개발자를 위해서 새로 고안되었습니다. 특히 이 코드블록은 기존에 미칠듯이 복잡하고 어려웠던 asp.net 인라인 코드를 좀더 html스럽게 보여줄수 있게되었다는 것에서 차별화 됩니다.
첫번째는 WebMatrix 를 설치하고 , 그 안에서 CSHtml 파일을 직접 작성해보는것이고 ,
두번째는 ASP.NET 프로젝트에서 Microsoft.WebPages.dll 을 참조하는 것 입니다.
애석하게도 아직 Visual studio 에서는 Razor 관련 인텔리센스를 지원하고 있지 않으나 , 스캇 블로그에서 이미 인텔리센스 데모를 선보이고 있기 때문에 빠른 시일내에 , 관련 자료가 배포될것으로 보입니다. 이와 관련된 내용은 발표되는대로바로 알려드리도록 하겠습니다.
Razor in WebMatrix
현재 가장 빠르게 Razor 를 접해보는 방법은 WebMatrix 를 설치하는 것 입니다. 설치에 대한 부분은 준서아빠님이 소개해주셨으니 간략하게 넘어가도록 하겠습니다. 설치에 대해서는 WebMatrix 설치부터 HelloWorld까지 를 참조해 주시기 바랍니다.
WebMatrix 를 설치하게 되면 처음에 Website1 이라는 페이지가 생성되어 있는 것을 알수 있습니다. Razor 를 간단하게 살펴볼수 있는 데모프로젝트라고 이해하시면 될거 같습니다. ^^
WebSite1을 더블클릭하거나 선택하고 Ok 버튼을 클릭합니다.
프로젝트를 로드하고 나면 한눈에 웹 페이지의 상태를 볼수 있는 화면이 나옵니다. Url 과 소스코드가 있는 폴더가 나오고 있네요. 일단은 Run 버튼을 눌러 사이트를 구동시켜보도록 하겠습니다.
깔끔한 웹 페이지가 나오네요. 이 페이지는 Razor 과 간단한 html 로 구성되어 있습니다. 그럼 한번 코드를 보도록 하겠습니다.
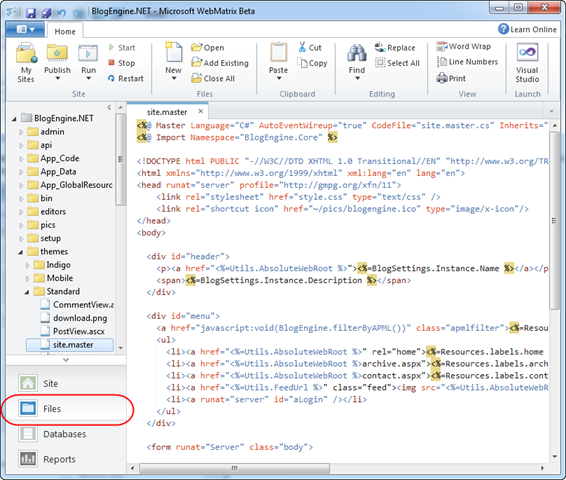
Files를 클릭하면 현재 구동중인 웹 사이트 프로젝트를 수정할수 있습니다. 이곳에서 우리는 default.cshtml 을 살펴보도록 하겠습니다.
이번 글에서는 WebMatrix 에 포함된 기본 프로젝트에서 Razor 를 사용하는 부분과 함께 , 외부 함수를 끌어오고 기존의 프로그래밍 경험을 접목시켜보는 것을 보여드렸습니다. 다음 글에서는 외부 함수를 직접 구현하고 그 함수를 사용하는 방법에 대해 알아보도록 하겠습니다.
추가된 부분은 굵은글씨로 표시하였습니다. 일단, grid.locale-en.js를 추가해야되더라고요^^; 디폴트로 그냥 jqGrid 스크립트를 넣을때 추가하라고 하였는데, 제가 지난 포스팅때는 빠뜨렸죠.
이런 언어 스크립트 파일에는 페이징 관련한 디폴트 값들이 들어가 있습니다.
defaults:{
recordtext:"View {0} - {1} of {2}",
emptyrecords:"No records to view",
loadtext:"Loading...",
pgtext:"Page {0} of {1}"
}
나머지 프로퍼티에 대한 설명을 드리자면, pager는 위 이미지 보이시죠? ^^; 저렇게 레코드들을 이동할수 있게 해주는 페이징 바를 정의합니다.
저같은 경우는 $('#pager')로 jQuery 표현을 썼는데요, jqGrid의 wiki를 보니 '#pager', 'pager', jQuery('#pager') 세가지 경우가 모두 가능한데요. 앞에 두가지 방법을 추천한다네요. 흠. jQuery 변수가 내보내기, 가져오기 모듈을 이용할때 문제를 발생시킬수 있다고 합니다. 이 부분은 차츰(?) 찾아보도록 하죠;;
The definition of the pager in the grid can be done this way:pager : '#gridpager', pager : 'gridpager' or pager : jQuery('#gridpager'). All the three methods are valid, but I recommend to use the first or second one, since the jQuery variant causes problems when we try to use Exporting and Importing modules.
emptyrecords는 말 그대로 데이터가 없을 때 표현할 문구를 나타내고요, rowNum은 페이지에서 보여줄 레코드 갯수, rowList는 페이지 갯수를 선택할 수 있도록 하는 셀렉트박스의 옵션들, sortname, sortorder는 각각 정렬할 컬럼과 정렬방식(오름차순, 내림차순), viewrecords는 토탈 레코드의 수(위 이미지에서 View 1 -3 of 5)를 표현하는 것을 허용할 것인지 여부를 나타냅니다.
이제 뷰페이지는 완성이 되었고요, 컨트롤러 손봐야겠죠?
EntityGridData() 라는 이름의 액션메쏘드를 추가하겠습니다.
[HttpPost]
public ActionResult EntityGridData(string sidx, string sord, int page, int rows)
{
// 데이터베이스 연결
MvcDbEntities _db = new MvcDbEntities();
// 페이징 변수 세팅
int pageIndex = Convert.ToInt32(page) - 1;
int pageSize = rows; // 3
int totalRecords = _db.TelDirSet.Count();
int totalPages = (int)Math.Ceiling((float)totalRecords / (float)pageSize);
var jsonData = new
{
total = totalPages,
page = page,
records = totalRecords,
rows = (
from dir in dirs
select new
{
i = dir.dirId,
cell = new string[] {
dir.dirId.ToString(), dir.name.ToString(), dir.phone.ToString(), dir.email.ToString(), dir.speedDial.ToString()
}
}).ToArray()
};
return Json(jsonData);
}
정규 강좌를 올리기 전에, 몇 가지 Windows Azure에 관련된 국내외 소식을 종합하는 업데이트 아티클들을 올려봅니다. 이번 업데이트에 반영된 내용들은 Windows Azure를 개발 플랫폼으로 택하시는 데에 있어서 중요한 정보들을 많이 포함하고 있습니다.
1. Windows Azure Tools for Visual Studio 1.2, Windows Azure SDK 1.2, Windows Azure Platform Training Kit 2010.06 업데이트 및 Windows Azure Tools 한글화!
Windows Azure Tools for Visual Studio, Windows Azure SDK, Windows Azure Platform Training Kit의 새 버전이 출시되었습니다. 이번 버전에서 가장 중점적으로 개선된 것은 Visual Studio 2010과의 연동과 .NET Framework 4.0에 대한 지원이며, 특히 최근에 중국어 간체, 중국어 번체, 일본어, 한국어 등 영어 이외의 다수 언어를 위한 Language Pack까지 같이 업데이트된 것이 주목할만한 점입니다. 아직 정식 Windows Azure 서비스가 출시되지는 않았지만 개발 도구에 대한 준비가 좀 더 완벽해진 것은 반길만한 일입니다. 이에 대한 자세한 내용은 http://www.rkttu.com/410 를 참고해주십시오.
2. Windows Azure AppFabric 2010.07 업데이트 및 SDK 출시
Windows Azure Tools for Visual Studio 1.2와 Windows Azure SDK 1.2 출시와 더불어서 Windows Azure AppFabric의 새 버전이 업데이트되었습니다. 이번 버전에서는 모바일 및 웹 브라우저 기반의 클라이언트 및 Microsoft Silverlight, Adobe Flash 기반의 RIA 클라이언트에서 직접 Service Bus나 Access Control에 접근할 수 있도록 개선된 것이 가장 큰 주안점입니다. 특히 RIA 클라이언트에서 AppFabric Service Bus나 Access Control에 접근하는데에 있어서 가장 큰 장애 요소였던 Cross Domain Policy에 대한 지원이 추가되었습니다. 더불어서 Windows Azure AppFabric SDK의 이번 버전에서는 .NET Framework 4.0에 대한 지원이 추가되었습니다. 좀 더 자세한 내용은 http://www.rkttu.com/414 를 참고하여 주십시오.
3. Codename: Dallas @ WWPC2010 업데이트
Codename: Dallas는 Windows Azure Platform과 더불어서 같이 제공되는 새로운 유형의 데이터 공급자 서비스로 각종 프리미엄 통계 자료, 뉴스, 동향 등의 정보를 ATOM, XML, Open Data Protocol 등의 데이터 형식을 이용하여 손쉽게 가져올 수 있습니다. 현재 확정된 데이터 공급사 (NASA, National Geographic, Associated Press, Zillow.com, Weather Central, NAVTEQ 등)외에도 아래의 그림에서 언급하는 추가 제공사들을 포함하여 올해 4분기에 Codename: Dallas가 정식 서비스로 전환될 예정에 있으며, 8월 중에 새로운 UI를 포함하는 CTP가 런칭될 예정이라고 합니다. 이에 대한 원문 기사는 http://blogs.msdn.com/b/zaneadam/archive/2010/07/12/news-on-microsoft-codename-dallas-at-wwpc-2010.aspx 에서 확인하실 수 있습니다.
4. Windows Azure Platform Appliance 발표
그 동안 Windows Azure Platform 자체는 전형적인 Public Cloud Platform으로서 잘 알려져있었고, 이에 대한 Counter Product로 Hyper-V나 System Center 등의 제품군이 Private Cloud Platform으로 소개되는 일이 많았습니다만 Windows Azure Platform의 기술 자체를 Private Cloud Platform화 하는데에 필요한 새로운 제품을 런칭하였습니다. 좀 더 자세한 정보는 http://www.rkttu.com/412 에서 확인하실 수 있습니다.
다음 강좌부터는 한글화된 Windows Azure Tools for Visual Studio 2010을 기반으로하는 Twitter Style의 Azure Guestbook 만들기 Walkthrough 강좌를 진행할 예정입니다. 많은 관심 부탁드립니다. :-)
이번 시간은 jQuery 플러그인인 jqGrid를 잠깐(?) 사용해보는 시간을 갖도록 하겠습니다.
jqGrid 플러그인 다운
먼저, jqGrid 사이트에서 jqGrid 플러그인을 다운받습니다.
다운받은 압축파일을 푸신 후, ASP.NET MVC 프로젝트에 3개의 파일을 추가하겠습니다. jquery.jqGrid.min.js 파일과 jquery-ui-1.7.1.custom.css, ui.jqgrid.css 파일입니다.
위 소스를 잠깐 살펴보면, url은 Home 컨트롤러에서 GridData라는 액션메쏘드를 호출하고 있습니다. 잠시 후에 이를 구현해야겠죠?^^; datatype은 json이네요. 음.. GridData라는 놈이 json객체를 넘겨주겠군?! 하고 생각하시면 되죠. colNames는 리스트를 보여줄때 각각의 컬럼을 구분짓는 이름입니다. colModel을 통해 grid에서 받을 리스트에 width라던지 align을 주고 있는 것을 보실수 있습니다.
그래서 완성된 Index.aspx 뷰페이지를 보게되면,
<%@ Page Language="C#" MasterPageFile="~/Views/Shared/Site.Master" Inherits="System.Web.Mvc.ViewPage" %>
<asp:Content ID="Content1" ContentPlaceHolderID="TitleContent" runat="server">
홈 페이지
</asp:Content>
이제, Home 컨트롤러를 잠깐 손보도록 하겠습니다. jqGrid에서 받을 json객체를 리턴하는 GridData라는 액션메쏘드를 만들도록 하겠습니다. 이번 포스팅은 정말 맛보기이기 때문에 간단하게 바로 객체를 만들어서 리턴하겠습니다.
와우~ 정말 간단하게 모든 구현이 완료되었습니다! 이제 실행을 해볼까요?
엥? 이건 또 뭔가요? 역시 한번에 되는 것은 없나봐요;;
내용을 보니 GET 요청이 차단되었고, JsonRequestBehavior를 AllowGet으로 설정하라고?! 호출 스택을 보니 JsonResult를 실행하다가 에러가 발생하였네요. 음.. JsonResult 부분이 잘못되었군. 한번 수정해보죠^^;
return Json(dirs, JsonRequestBehavior.AllowGet);
수정후 실행해보면~
네. 멋지게 성공하였습니다.
ASP.NET MVC 2 에서는 기본적으로 이러한 GET방식의 호출을 보안상의 문제로 막아놨습니다. 그래서 JSON 객체를 리턴할때는 JsonRequestBehavior.AllowGet을 추가하여 클라이언트의 GET요청을 허용하도록 한 것이죠.
하지만, 막아놓은 것을 굳이 풀 필요는 없겠죠?^^; POST 방식으로 호출하는 것이 좀더 좋을 듯 합니다.
이 부분은 따로 설명드릴 필요없겠죠? 약간(^^;;) 설명드리면~
일단 GridData액션 메쏘드 위에 GET으로 요청한 놈은 접급하지마! 라는 표지판([HttpPost])을 세워두는거죠. 실행시켜보면 역시 에러가 발생할겁니다. 리소스를 찾을수 없다는... 그래서! 뷰페이지 스크립트 부분의 mtype을 POST로 수정하는거죠^^ 실행해보세요~ 잘되시나요?
이거슨 번외요~
웹 개발자를 위한 Web Development Helper 유틸이 있습니다. 익스플로러에 확장할 수 있죠. 저같은 경우는 Fiddler를 많이(?) 사용하는데요. Web Development Helper는 특히 Ajax와 ASP.NET 개발자를 위한 것이라고 하네요. 사이트에서 다운 받고 인스톨하시고, 익스플로러의 도구 메뉴의 탐색창->Web Development Helper를 클릭하시면 됩니다.
이번 jqGrid 맛보기에서의 request&response정보도 확인할 수 있네요.
마무리요
이번시간은 정말 jqGrid 플러그인의 맛보기였고요, 다음 포스팅에서 뵙도록 하겠습니다. (다음 포스팅도 맛보기처럼 보이면 어떡하죠?^^;;)
지난 포스팅에서는 드디어 WM_TOUCH를 이용한 멀티터치 UX의 구현방법에 대한 이야기가 시작되었습니다. channel9에 공개된 예제를 함께 작성해 보면서 WM_TOUCH 메세지를 다루는 방법을 알아보고 있는데요, 어떨 때 WM_TOUCH를 이용해야 하는지, WM_GESTURE가 아닌 WM_TOUCH를 받고 싶을 땐 어떻게 처리해 주어야 하는지, 그리고 메세지를 받을 때마다 호출되는 CWnd::OnTouchInput 등에 대한 설명이 있었습니다.
그리고 실제로 OnTouchInput() 함수에서 터치 메세지를 제어할 예제 프로그램인 ‘TouchPad’ 프로젝트를 생성하고 기본적인 전처리 단계를 알아보았지요. 이에 이어서 오늘은 OnTouchInput() 함수의 구현부터 본격적으로 알아보도록 하겠습니다 ^^
Task 3 : 드로잉 코드는 가져다 씁시다. 터치에 집중해야죠 ㅎㅎ
지금 함께 작성해 보려고 하는 TouchPad는 윈도우 그림판처럼 멀티 터치 입력에 대해 라인을 그려주는 예제입니다. 한 발 더 나가서, 서로 다른 입력으로 드로잉 하는 라인은 색상도 다르게 표시되도록 할거예요. 하지만 사용자로부터 입력된 터치 정보의 처리방법에 집중하기 위해, 드로잉 코드는 샘플에서 제공된 클래스를 사용하도록 하겠습니다. 먼저 예제 프로젝트에 아래의 파일을 추가해 주세요.
이 클래스들을 이용해 우리가 구현할 코드에 대해 간략히 설명해 보기로 하지요. 우리는 각각의 터치 입력에 대해서 라인(stroke. 스트로크라고 부르겠습니다.)을 그려내는 기능을 추가할 것인데, 이를 이해서 두 개의 스트로크 모음을 유지할겁니다. 한 쪽에서는 이미 드로잉이 끝난 스트로크 데이터를 모아 유지하게 되고, 또 다른 나머지 한 쪽에서는 현재 터치입력으로 드로잉하고 있는 데이터를 유지하게 됩니다. 스크린을 터치하는 한 개 혹은 다수의 입력을 받아 m_StrkColDrawing 멤버변수가 유지하는 스트로크 정보에 CPoint 형식의 좌표 데이터를 추가합니다. 그리고 스크린에서 손가락을 떼면, 손가락을 따라 그려지고 있던 스트로크 정보를 m_StrkColDrawing 변수에서 m_StrkColFinished로 이동시킵니다. 이 때 동시에 다수의 터치 입력이 동시에 일어나면 이를 구분하기 위해 서로가 다른 색상을 가진 스트로크를 출력하게 할겁니다.
그럼 소스코드 상에서의 수정사항을 알아보기로 하지요. 먼저 위에 첨부되어있는 파일들을 다운받아서 프로젝트에 넣은 후, StdAfx.h 헤더파일에 새로 추가된 헤더들을 인클루드 해주세요.
// stdafx.h 파일에 추가해 주세요.
#include"Stroke.h"
#include"StrokeCollection.h"
그리고 ChildView.h 파일로 가서 CChildView 클래스에 private 멤버 변수로 아래의 세 변수를 추가해 줍니다.
private:
int m_iCurrColor; // The current stroke color
CStrokeCollection m_StrkColFinished; // The user finished entering strokes
// after user lifted his or her finger.
CStrokeCollection m_StrkColDrawing; // The Strokes collection the user is
// currently drawing.
이 중에서 m_iCurrColor는 드로잉 되는 스트로크의 색상을 결정하기 위한 인덱스로 쓰일 겁니다. 생성자에서 0으로 초기화 해주세요.
CChildView::CChildView() : m_iCurrColor(0)
{
}
드로잉이 다 끝나서 m_StrkColFinished 변수에 담겨 있을 스트로크 정보들을 화면에 출력해 주기 위해 CChileView::OnPaint() 함수에 아래의 코드를 추가해 줍니다.
// 드로잉이 완료된 스트로크 정보를 출력한다.
m_StrkColFinished.Draw(&dc);
Task 4 : 터치 데이터를 다뤄보자 (드디어!)
이제 드로잉 코드의 기본적인 설정들은 끝을 냈고, 지금부터 우리는 WM_TOUCH 메세지에 대해 아래의 세 가지 경우에 따른 코딩을 추가해 넣을 것입니다.
사용자가 스크린에 터치를 시작한 시점의 처리. – Touch Input Down
터치한 손가락을 스크린 상에서 움직이는 동안의 처리. – Touch Input Move
스크린에서 이동하던 손가락을 떼어 터치 입력이 끝나는 시점의 처리. – Touch Input Up
각각의 경우를 처리하기 위한 코드를 클래스에 추가해 봅시다. ChildView.h 헤더파일에서 위의 세가지 경우에 호출할 CChildView 클래스의 멤버함수를 선언해 줍니다.
각각의 함수 본문에는 터치가 발생한 시점에 걸맞는 드로잉 코드들이 구현되어 있습니다. 샘플 원본에는 영어로 달려있던 주석을 제가 한글로 바꾸고 추가 설명도 좀 덧붙여 두었습니다. 아직까지는 별다른 설명 없이 코드만 보더라도 어렵지 않게 이해하실 수 있을 거예요.
이 함수들의 본문보다 더 중요한 부분은, 이 함수들을 '언제 호출해 주어야 하느냐' 하는 점입니다. 멀티 터치 데이터의 입력 시점에 따른 상태를 확인하기 위해 주의깊게 확인해야 할 부분은 지난 포스팅에서 선언만 해두고 빈 함수 몸통만 덩그라니 남겨두었던 CChildView::OnTouchInput(...) 함수입니다. 이곳에서 현재 멀티터치 데이터를 조회해 현재 입력 시점이 어떻게 되는지, 혹은 부가적인 다른 정보들을 어떻게 얻어내는지를 알아보는 것이 이번 포스팅의 중요한 목표라고 볼 수 있죠. 아래의 코드를 유심히 봐주세요.
BOOL CChildView::OnTouchInput(CPoint pt, int nInputNumber, int nInputsCount, PTOUCHINPUT pInput)
{
if ((pInput->dwFlags & TOUCHEVENTF_DOWN) == TOUCHEVENTF_DOWN)
OnTouchInput 함수의 인자로 TOUCHINPUT 구조체의 포인터가 전달되는데, 이 구조체의 멤버 변수인 dwFlag에 담겨있는 flag의 상태를 조회함으로써 현재 터치 입력에 대한 여러 가지 정보들을 알아낼 수 있습니다. 위에 적힌 코드에서도 dwFlag를 이용해 터치 데이터의 추가 정보들을 알아내고 있습니다. 위의 함수 본문을 복사해 OnTouchInput 함수의 구현을 대체해 주세요.
이 중 일련의 멀티터치 입력이 처음 시작될 때의 처리를 위한 OnTouchInputDown(…) 함수를 한 번 보기로 하죠. 여기에서도 TOUCHINPUT 구조체의 dwFlag 를 조회하는 코드를 볼 수 있습니다. 바로 TOUCHEVENTF_PRIMARY 플래그가 켜져 있는지를 확인해 보는 코드네요. 입력중인 터치 정보가 여러 개인 경우, 이 중 가장 먼저 시작된 (PRIMARY) 터치 정보 인지를 확인하는 부분입니다. PRIMARY 터치는 스트로크의 색상을 검정으로 유지하고, 그렇지 않은 경우는 미리 정의된 몇 가지 색상 정보를 rotation해가며 결정해 주기 위해서 PRIMARY 데이터 여부를 확인하고 있습니다. 스트로크의 색상을 결정해주는 GetTouchColor() 함수의 선언 및 구현도 아래와 같이 추가해 주세요.
이제 추가해야 할 코딩의 마지막 입니다. 드로잉을 하면서 추가해 주었던 스트로크 정보들의 해제 처리를 소멸자에 넣어주세요. 멀티터치 데이터의 조작 방식을 알아보기 위한 이번 예제는 동적 메모리 할당의 효율적인 처리 같은 관점에서는 그다지 효율적이지 못합니다. 그래서 실행해보면 다소 반응 속도가 느리다고 느껴지실 수도 있습니다만, 이번 예제가 어디까지나 MFC 프로젝트에서 WM_TOUCH 메세지의 조작 방식을 알아보기 위함임을 감안해 주세요 ㅎㅎㅎ 그래도 양심상 할당한 메모리의 해제는 해주어야겠지요 ^^;… CChildView의 소멸자에 아래 코드를 넣어주시면 이제 코드 추가는 모두 완료입니다!
CChildView::~CChildView()
{
for (int i = 0; i < m_StrkColDrawing.GetCount(); ++i)
{
delete m_StrkColDrawing[i];
}
for (int i = 0; i < m_StrkColFinished.GetCount(); ++i)
{
delete m_StrkColFinished[i];
}
}
Task 5 : 프로그램을 실행하고 직접 스크린을 ‘멀티’터치해 봅니다.
이제 빌드하고 프로그램을 실행해 봅니다. 스크린 터치를 통해서 view 영역에 동시에 서로 다른 라인이 그려지는 기능을 직접 확인해 보세요. 샘플 프로그램을 훌륭하게 서로 다른 panning 제스처를 인식해 각각의 입력에 따른 스트로크를 출력하게 됩니다.
Outro
이번 글에서는 지난번 포스팅에 이어서 WM_TOUCH 메세지를 사용해 멀티터치 UX를 구현하는 TouchPad 예제를 완성해 보았습니다. WM_TOUCH 메세지가 발생할 때마다 호출되는 CWnd::OnTouchInput() 함수에서
Touch 입력의 시작, 진행 중, 종료 시점을 알아내는 방법
DWORD 타입의 ID값을 이용해 서로 다른 터치 입력을 구분하는 방법
동시에 여러 개의 멀티터치가 발생할 때, 먼저 일어난(primary) 터치 데이터를 구별하는 방법
… 등을 알아보았습니다. 또한 이를 활용해 동시 다발적인 멀티터치 입력에 대해 각기 다른 panning 제스처로 인식해 궤적을 그려내는 방법을 예제 구현과 함께 알아보았습니다. 이를 통해 WM_TOUCH 메세지를 제어하는 방법을 보다 쉽게 이해할 수 있으셨을 겁니다.
Native 코드로 멀티터치 UX를 구현하는 방법 중에 아직 소개해 드리지 않은 영역이 있습니다. MFC로 제공되는 기능은 아니지만, Com-Interface 형태로 제공되는 Manipulation(MS Surface에서와 같은 위젯 처리 기법. 한번에 여러 개의 제스처를 동시 적용한다.), Inertia(관성)의 제어기법 등이 그것입니다. 다음 포스팅에서는 이러한 부분에 대해서 알아보도록 하겠습니다.
바야흐로, 여름입니다.
아ㅡ 정말 이놈의 귀차니즘 덕분에 너무 띄엄띄엄 포스팅이 되는 것에 대해 죄송하다는 말씀 먼저 드려야할 것 같습니다.
여름이라 더워서 그렇다고 핑계대지 않을게요, 휴가 시즌이라 놀고 싶어서 그렇다고 핑계대지 않을게요~ ;;;
잡담은 여기서 줄이고, 힘을 내어, 이번 포스팅을 시작해 보겠습니다. 레츠 고우~
지난 포스트의 주제는 WAS 호스팅이었습니다. 이번 주제는 조금 다르긴 하지만 지난 포스트에 이어서 Hosting과 관련된 내용을 적어볼까 합니다.
WCF 서비스를 호스팅하기 위해 가장 쉬운 방법이 무엇인지 다들 아시죠?
제 개인적인 생각인지는 모르겠지만, Visual Studio를 사용하여 WCF 서비스를 만든다면, 아마도~ 가장 쉬운 호스팅 방법은 IIS 호스팅일 것입니다. 솔루션 만들고 별 수정없이 바로 호스팅이 가능하니깐요,,
갑자기 왜 IIS 호스팅에 대한 얘기를 꺼내냐구요?
음,, 오늘 제가 꺼낼 이야기가 IIS 호스팅일 때 WCF 서비스에 ASP.NET의 몇 가지 특성을 적용할 수 있는 방법에 대한 내용을 적으려다 보니... 네!! 결국, 제가 하고 싶은 얘기는 이번 포스팅에서 나오는 방법들이 IIS 호스팅을 바탕으로 한다는 것을 명심(?)해 달라는 것입니다. ㅎㅎ
닷넷 웹 서비스 와 WCF 서비스
WCF 서비스 얘기를 할 때, 가장 비교를 많이 하는 것이 아마 .NET 웹 서비스 일 듯 합니다. (지금도 이 닷넷 웹 서비스에 대해 얘기를 하려 하구요~ ㅎ)
닷넷 웹 서비스와 WCF 서비스의 가장 큰 차이는 무엇일까요?
구현하는 방법에 대한 차이도 있겠지만, 그것보단 WCF 서비스가 HTTP 프로토콜 이외의 프로토콜(net.tcp, net.pipe, MSMQ)을 이용하여 접근이 가능하게 호스팅할 수 있다는 점일 것입니다. (WAS를 이용한 호스팅 참조)
닷넷 웹 서비스는 WCF 서비스와는 다르게 HTTP 프로토콜만 지원합니다. 그리고 이는, ASP.NET HTTP 파이프라인을 따르고 있습니다.
"아ㅡ ASP.NET 파이프 라인은 또 뭔가요?" 라고 원망 섞인 소리가 여기까지 들리는 것 같습니다. 저도 아직 실력이 미천한 개발자라 자세히 설명드릴 수는 없습니다.
간단하게 설명 드리자면, ASP.NET 에서 Http 프로토콜을 이용하여 들어오는 요청(request)과 응답(response)을 처리하기 위한 파이프라인입니다. 즉, 어떤 요청에 대해서 어떻게 필터링을 수행하고, 어떤 어플리케이션을 호출할 것인지를 처리하며, 파이프라인을 통해서 그에 대한 응답을 전송하는 것입니다.
닷넷 웹 서비스는 이렇게 ASP.NET HTTP 파이프라인을 사용하기 때문에 많은 ASP.NET 의 특징을 함께 사용할 수 있다는 장점을 가지고 있습니다. 이러한 장점에는 다음과 같은 것들이 포함 됩니다.
Authentication
Url/File authorization
Impersonation
Session state
Request cache
Globaliztion
Etc
목록을 보니 인증과 권한에 대한 것, 그리고 세션과 관련한 것들이 있네요~
이제 WCF 서비스 얘기를 해볼까요?
WCF 서비스는 닷넷 웹 서비스와는 다르게 non-HTTP 프로토콜들을 지원해줍니다. 그리고, 이러한 장점을 위하여 프로토콜에 독립적인 디자인을 사용하게 된 것입니다.
조금 둘러서 얘기를 했지만, 제가 하고 싶은 말은 이것입니다.
"닷넷 웹 서비스와는 다르게 WCF 서비스는 ASP.NET HTTP 파이프 라인을 따르지 않는다!!"
음,, 그렇군요. WCF 서비스는 ASP.NET HTTP 파이프 라인을 따르지 않는군요... 앗~ 그렇다면 닷넷 웹 서비스의 경우 ASP.NET HTTP 파이프 라인을 따랐기에 여러가지 ASP.NET의 특성을 사용할 수 있었는데,, 그럼, WCF 서비스에서는 ASP.NET의 특성들을 사용할 수 없는걸까요??
네~!! 기본적으로는 그렇습니다.
하!지!만!!! ASP.NET 에는 여러 유용한 특성들이 존재했기에 이를 완전히 버리기는 아까웠을겁니다. WCF 서비스를 위해서 같은 특성들을 다시 만들기 보다는 기존에 있던 것들을 가져다 쓰는 방향으로 개발하고 싶었겠지요~(제 개인적인 생각입니다. 아니면 말구요~ ㅎ)
어떤 이유인지는 확실치 않지만, 어찌됐든 중요한 것은, WCF 서비스에서도 기존의 ASP.NET 특성들을 (전부는 아니고 일부분의 특성들을) 사용할 수 있는 방법을 제공해주고 있다는 것입니다. 단, HTTP 프로토콜을 사용하는 WCF 서비스에서만요~
이번에도 역시 둘러둘러~ 이제서야 본론으로 들어온 것 같습니다 ^^
그럼, 이제 본격적으로 WCF 서비스에서 ASP.NET의 유용한 기능들을 사용하기 위한 방법에 대해서 얘기해보도록 하겠습니다.
WCF 서비스에서 Session 사용하기
이번 포스팅에서는 ASP.NET의 특징들 중에서 간단하게 Session을 사용하는 예제를 구현해보려 합니다. (차후에 WCF의 보안에 대해 포스팅을 할 때에는 Impersonation 과 관련한 예제도 보여드릴 수 있을 것 같습니다.)
여기서 Session은 WCF 의 인스턴스를 생성할 때의 모드인 InstanceContextMode.Session 과는 전혀 무관합니다. 다들 알고 계시리라 생각하지만 혹시나 싶어서요~ ㅎ
우선, ASP.NET의 특징들을 사용하기 위해서는 크게 두 가지의 설정이 필요합니다.
첫 번째, Application Level 에서의 설정이 필요한데, 이는 WCF 서비스 프로젝트의 web.config에서 <system.serviceModel> 의 자식 요소인 <serviceHostingEnvironment> 요소의 속성 aspNetCompatibilityEnabled 의 값을 true로 명시하여 설정할 수 있습니다.
두 번째로, Service Level 에서의 설정이 필요합니다. 이는 WCF 서비스를 구현하는 클래스에 AspNetCompatibilityRequirements 특성을 통해 설정을 할 수 있습니다.
코드를 보면서 하나씩 해보도록 하죠~
WCF 솔루션을 하나 만듭니다. 좀 편하게 작업을 하기 위해서 셀프 호스팅보다는 Visual Studio 에서 제공해주는 "WCF 서비스 응용 프로그램" 템플릿을 사용하도록 하겠습니다.
그리고, 다음과 같이 서비스 계약을 위한 interface와 WCF 서비스에서 사용할 개체인 Product 클래스를 정의했습니다.
[ServiceContract]
publicinterfaceIProductService
{
[OperationContract]
Product GetProduct(string ticker);
}
[DataContract]
publicclassProduct
{
[DataMember]
publicstring Name;
[DataMember]
publicint calls;
[DataMember]
publicdouble price;
[DataMember]
publicstring RequestedBy;
}
이 다음에 할 일은 당연히 서비스를 구현하는 것이겠죠.
이 서비스에서는 session을 사용하여 현재 메서드가 호출되는 횟수를 기록, 유지하도록 했습니다.
이 코드에서 다시 한번 유의해서 보아야 할 부분은 역시 ProductService 클래스 위에 선언 된 AspNetCompatibilityRequirements 특성입니다. 그 값을 Required 로 주었네요~
이 부분은 앞에서 ASP.NET 특성들을 사용하기 위한 설정 중 Service Level에서의 설정에 해당하는 것이었습니다.
그럼, 이제 Application Level에서의 설정을 해주어야 겠군요.
web.config 파일을 다음과 같이 수정합니다.
이 코드에선 그렇게 중요한 부분이 없습니다. 단순히 서비스의 GetProduct 메서드를 연속해서 5번 호출을 해주는 것 밖엔,, 복잡한건 싫으니깐 이렇게 간단히~ ㅎ
그리고 실행을 해보도록 하죠~
앗~ 뭔가 이상합니다. 우리가 예상했던 그런 결과가 나오지 않는군요. 세션이 유지가 되었다면 호출 횟수의 값이 1씩 증가하여 1~5의 값을 보여주어야 할텐데 말이죠.......
이런 결과가 나오는 이유는 바로,, Session을 사용하기 위해서는 클라이언트에서 쿠키를 허용해주어야 하는데, 기본 HTTP 바인딩인 basicHttpBinding 과 wsHttpBinding이 기본적으로 쿠키를 허용하지 않기 때문입니다.
HTTP 바인딩에서 쿠키를 허용해주기 위해선 config 파일에서 binding 태그의 allowCookies 속성의 값을 true 로 바꿔주시면 됩니다. 다음과 같이 말이죠~
문득, 서비스의 InstanceContextMode의 값이 바뀌면 어떻게 될지 궁금해지지 않으신가요? ㅎ
한번 직접 해보시면 알겠지만 이 세션은 InstanceContextMode의 값(PerSession, PerCall, Single)이 무엇이 되든지 간에 유지됩니다. (다들 한번씩 해보시길~ ^^)
이번 포스팅은 여기까지하고 줄이도록 하겠습니다.
사실 이 포스팅은 제가 월드컵이 시작할 때 같이 시작했었는데, 결국 월드컵이 끝날 때 같이 끝나게 되었네요,,
이 놈의 귀차니즘 덕분에 포스팅이 항상 늦게 올려져서,, 정말 죄송한 마음밖엔 없는 것 같습니다.
일을 하면서 포스팅을 한다는 것 자체가 쉬운 일이 아님을 깨달았습니다.(MVP 분들이 존경스러워 지는군요,,ㅎ) 그래도 포기하면 안되겠죠,, ㅎ
이전 글까지 Asynchronous Agents Library( 이하, AAL ) 의 일부인 agent 와 message 전달 함수에 대해 알아보았습니다. agent 만 알아도 어느 정도 비 동기 처리를 쉽게 구현할 수 있습니다.
이번 글에서는 agent 간 소통을 할 수 있는 message block 들에 대해서 알아보겠습니다. message block 을 이용하면 agent 간 데이터 또는 상태 동기화를 할 수 있습니다.
AAL 은 스레드로부터 안전한 방식으로 구현되었고, 추상화되었습니다. 그래서 agent 객체와 message block 을 이용한 동기화 로직이 직관적이고 쉽게 흐름을 파악할 수 있어 데드락( dead-lock ) 을 방지하기 용이합니다.
그럼 지금부터 agent 를 이용한 비 동기 처리에 날개를 달아주는 message block 에 대해 알아보도록 하겠습니다.
Message 객체
예전 글부터 message, message 메커니즘, message 전달 함수, message block 등을 언급하면서 항상 message 란 개념을 사용했습니다.
이 개념은 실제 클래스로 존재합니다. 하지만 단지 message 를 래핑( wrapping ) 할 뿐, 전혀 다른 기능을 가지고 있지 않은 클래스입니다.
한 가지 기능이 있다면 식별자( id )를 갖는다는 것입니다. message 클래스는 Concurrency Runtime 의 _Runtime_object 클래스를 상속 받습니다. 이 클래스는 Runtime 에 의해 생성될 때 자동으로 id 를 갖게 됩니다. 이 id 를 알아보는 함수는 msg_id() 입니다. 이 메서드의 접근자가 public 으로 되어 있어 message 클래스에서도 사용 가능합니다.
이 msg_id() 가 반환한 값은 message block 에서 사용되는 runtime_object_identity 형입니다. 몇몇 message block 메서드의 runtime_object_identity 형의 매개변수에 인자로 사용할 수 있습니다.
사실, 직접 message block 을 구현하지 않는 한, message 클래스는 직접 사용할 경우는 없을 것입니다. 우리는 보내고 받는 데이터를 공급하면 내부적으로 그 데이터를 message 클래스로 래핑하고 message block 내부에서 사용하게 되는 것입니다. 그러므로 크게 신경쓰지 않아도 됩니다.
Source 와 target
Message block 은 크게 두 가지 종류로 나눌 수 있습니다. 하나는 source 이고 다른 하나는 target 입니다.
Message block 에서의 source 는 message 를 보낼 message block 을 일컫습니다. 마찬가지로 target 은 message 를 받을 message block 을 뜻합니다.
ISource 인터페이스
Source 는 AAL 의 하나의 개념이지만, 이것을 인터페이스로 추상화 하였습니다. 이것이 ISource 인터페이스입니다.
그러므로 source 로 쓰일 message block 들은 ISource 인터페이스를 상속하여 구현되었습니다. 만약 직접 source 로 사용될 message block 을 구현하신다면
ISource 인터페이스를 상속해야 합니다.
- ISource 인터페이스의 선언
template< class _Type>class ISource;
[ 코드1. ISource 인터페이스의 선언 ]
템플릿 매개변수인 _Type 은 message 로 쓰일 데이터 형( type )입니다. _Type 은 public typedef 인 source_type 으로 사용할 수 있습니다.
link_target() 은 target 인 message block 과 연결합니다. 여기서 연결의 의미는 자동으로 전달된다는 의미로 생각하시면 되겠습니다.
즉, 이 ISource 를 상속받은 message block 에 link_target() 으로 target message block 을 연결했을 경우, 이 message block 의 message 들은 직접 전달 함수를 사용하지 않아도 자동으로 target message block 으로 전달됩니다.
연결할 target 은 여러 개일 수 있습니다. 그러나 ISource 를 상속한 message block 의 구현에 따라 첫 번째 target 만 동작할 수도 있습니다. 예로 unbounded_buffer 가 있습니다. unbounded_buffer 는 내부적으로 큐를 구현하고 있어 전달 후, message 가 큐에서 제거되므로 두 번째 연결된 target 이 있더라도 message 를 보낼 수 없습니다.
매개변수인 _PTarget 은 연결할 target message block 입니다. _PTarget 의 데이터 형인 ITarget 은 target 을 추상화한 인터페이스입니다. 곧 설명하도록 하겠습니다.
accept() 는 target 에서 호출되지만, source 가 제공합니다. source 의 message 를 수락하고, 소유권이 이전됩니다.
매개변수인 runtime_object_identity 는 message 객체의 msg_id() 로 얻을 수 있습니다. 실제로 runtime_object_identity 는 __int32 를 typedef 한 것이고, Concurrency Runtime 에서 객체를 생성할 때 지정되는 고유의 번호입니다.
release_ref() 는 참조 개수를 감소시킵니다. 현재 link_target() 으로 연결된 target 에서 호출됩니다.
매개변수인 _PTarget 은 link_target() 으로 연결된 target 입니다.
ITarget 인터페이스
Target 또한 source 와 마찬가지로 AAL 의 하나의 개념이지만, 이것을 추상화 하였습니다. 이것이 ITarget 인터페이스 입니다.
Target 으로 사용할 message block 을 구현하신다면 ITarget 인터페이스를 상속해야 합니다.
- ITarget 인터페이스의 선언
template< class _Type>class ITarget;
[ 코드11. ITarget 인터페이스의 선언 ]
템플릿 매개변수인 _Type 은 message 로 사용될 데이터 형입니다. _Type 은 public typedef 인 type 으로 사용할 수 있습니다.
Target 은 필터를 지정할 수 있습니다. 그래서 필터 함수의 시그니처( signature )인 bool ( _Type const & ) 를 typedef std::tr1::function<bool(_Type const&)> filter_method 로 정의되어 있습니다.
즉, WebMatrix&Razor 는 빠르게 웹 개발 환경을 구성하고 Razor 의 뷰(View) 엔진을 이용하여 신속하게 웹 페이지를 개발하고자 합니다. 웹 환경/웹 개발/데이터베이스/웹 개발 도구 등 WebMatrix&Razor 에 모두 포함이 되어 있습니다.
아마도 처음 웹 개발에 접하시는 분들이 처음 갖는 고민은..? 웹 환경 구성/웹 프로토콜 및 통신의 이해/호스팅 등 복잡했던 초기 작업을 매우 효과적이고 간소화하여 신속하게 작업을 진행할 수 있는 장점이 있습니다.
WebMatrix 란 무엇인가요?
WebMatrix 는 약 15MB 의 용량으로 빠르게 웹 개발 환경을 갖출 수 있습니다. (단, .NET Framework 4.0 이 인스톨 되지 않았을 경우 약 50MB). 현재 WebMatrix 는 Beta 버전이며 이 링크를 클릭하시면 다운로드 받으실 수 있습니다.
이 웹 WebMatrix 에는 다음의 구성 요소가 포함이 되어 있습니다.
IIS Express
SQL Compact Edition
ASP.NET Extensions
그리고 Visual Studio 2010 또는 Visual Web Development 2010 Express 개발 도구를 이용하여 웹 개발 또는 커스터마이징을 하실 수 있습니다.
WebMatrix 는 쉽게 사용할 수 있게 설계가 되었습니다.
초기 웹 개발 환경은 웹 페이지를 만들기 위해 해야 할 일들이 많았습니다. 환경 구성/개발 환경 구성 등 말이죠.
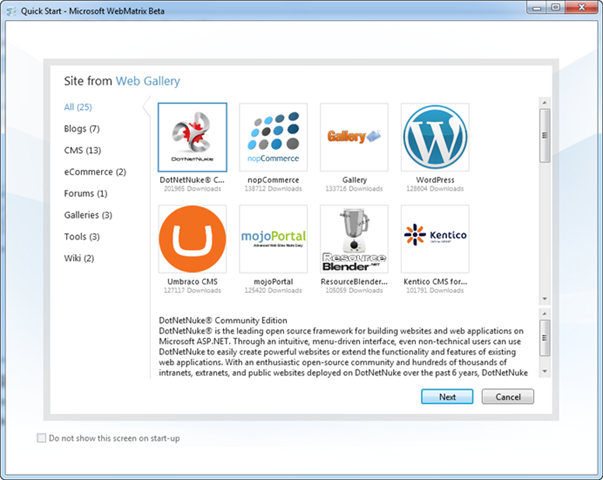
WebMatrix 는 아래와 같이 매우 심플한 디자인으로 웹 개발의 시작을 빠르고 쉽게 수행할 수 있습니다. Site from Web Gallery 는 오픈 소스 웹 어플리케이션을 바로 설치하여 사용할 수 있고, Site From Template 으로 최적화된 환경에서 개발을 시작할 수 도 있습니다.
Site From Web Gallery 는 온라인에서 인기 있는 다양한 오픈 소스 웹 어플리케이션이 포함되어 있답니다. ASP.NET, PHP 의 오픈 소스 웹 어플리케이션이 포함되어 있으며, 설치나 배포가 매우 간단합니다.
그 중, Scott 님은 BlogEngine.NET 으로 예제를 보여주시네요. BlogEngine.NET 는 이미 예전부터 CodePlex 를 통해 오픈 소스로 공개가 되고 현재도 인기 있는 블로그 웹 어플리케이션입니다.
BlogEngine.NET 을 선택하고 Next 버튼을 클릭하면 이것을 설치하기 위한 컴포넌트를 체크하거나 다운로드 받습니다. 즉, 원클릭(One-Click) 으로 어플리케이션이 동작하기 위한 모든 환경을 스스로 구성한다는 얘기죠^^
PHP 어플리케이션의 경우 WordPress, Drupal, Joomla, Sugar CRM 등은 MySQL 이 필요한데, 개별적인 설치 없이 이런 환경도 자동으로 다운로드 받아 설치를 합니다.
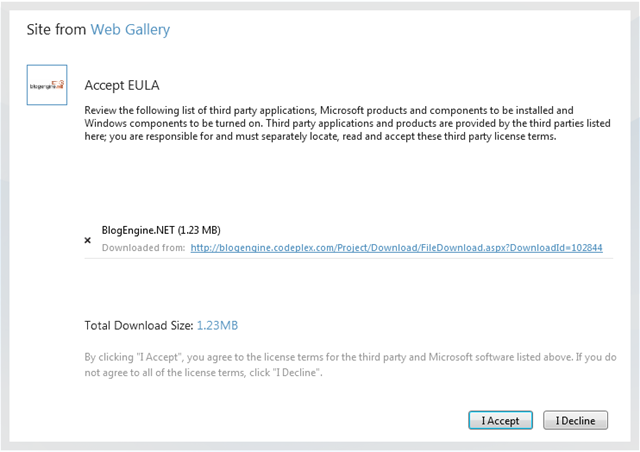
간단하게 소프트웨어 사용권 동의(EULA) 를 클릭하면 바로 설치와 구성 작업을 시작합니다.
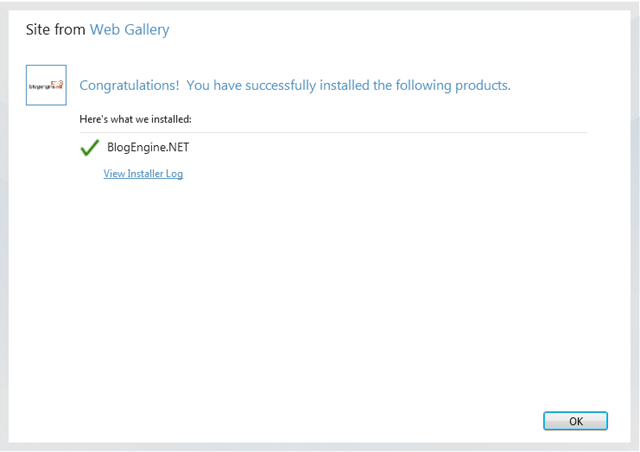
그리고 금새 설치와 구성이 완료가 되었지요^^
모든 구성이 완료되면, 아래와 같은 Overview 페이지가 나타납니다.
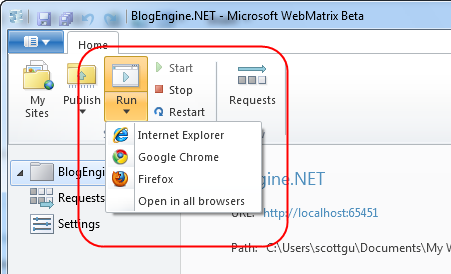
설치된 BlogEngine.NET 을 실행하기 위해서 아래의 Run 버튼을 클릭합니다. 인터넷 익스플로러, 크롬, 파이어폭스로 실행할 수 있고, Open in all browsers 로 여러 브라우저로 한꺼번에 실행할 수 있습니다.
자! 여태까지 클릭 클릭만 했는데, 아래와 같이 BlogEngine.NET 이 설치되고, 구성되고, 모든 구성이 완료가 됩니다.
초기 관리자 아이디와 비밀번호는 admin/admin 입니다. 관리자로 로그인 하셔서 블로그의 이름을 달아주시고, 블로그 저자 소개 등을 입력해 주시면, 곧바로 블로그를 운영을 준비하셔도 될 것 같습니다.^^
WebMatrix 는 오픈 소스 웹 어플리케이션을 커스터마이징 할 수 있는 약간의 개발 환경도 제공해 줍니다. 아래와 같이 소스 코드를 변경할 수 도 있고, Files 버튼으로 파일을 편집하거나 추가, 삭제를 할 수 있습니다.
이제 블로그를 운영하기 위해 배포와 호스팅을 해야 합니다.
WebMatrix 의 특징은 매우 경량화되었고 작업 환경이 통합된 장점을 갖습니다. 로컬 또는 원격 웹 서버로 배포할 때, FTP 또는 FTP/SSL 또는 Microsoft Web Deploy(MSDeploy) 를 이용하여 쉽게 배포가 가능합니다.
아래의 Publish 버튼을 클릭하면 배포 준비가 시작됩니다.
배포 세팅 화면은 아래와 같습니다. 서버의 기본 정보를 입력하고, 데이터베이스의 연결 문자열을 입력한 후에, Publish 버튼을 클릭합니다.
모든 준비가 완료되었고, Publish 버튼을 누르면 이제 배포를 시작할 준비가 완료 되었습니다.
이하.. 금일 Microsoft Korea 의 김대우 과장님께서 진행하는 WebMatrix&Razor 세미나에 참석하기 위해 이만 줄입니다. 다른 분들께서 더 알차고 재미있게 포스팅 해 주시리라^^
최근의 소프트웨어 개발은 점차적으로 엔터프라이즈화 되어 가고 있습니다. 대용량/대규모화 되어가고 있는 현대의 소프트웨어 생태계에서 마치 새로운 트랜드로 자리잡고 있는 엔터프라이즈 2.0 이 자리를 잡고 그 규모를 넓혀가고 있습니다. 엔터프라이즈 2.0 은 Web 2.0 과 결합된 의미로써 즉, Enterprise social software(http://en.wikipedia.org/wiki/Enterprise_2.0) 라고 보아도 크게 의미는 다르지 않습니다.
엔터프라이즈 소프트웨어는 대용량/대규모/보안 등의 핵심 키워드로 그 아키텍처가 매우 민감한 부분이기도 합니다. 하지만 엔터프라이즈 2.0은 기존 엔터프라이즈에 개방/공유 등을 강조하면서 바로 협업과 맞물리는 부분이기도 합니다. 그리고 이러한 움직임은 국가적인 차원의 거버먼트 2.0(http://blog.powerumc.kr/252)과 매우 유사하기도 합니다.
즉, 중요한 것 중 현대의 소프트웨어 개발은 더 이상 폐쇄적인 환경을 거부하며, 최소한의 자원과 리소스를 아끼고, 남은 자원을 극대화하여 새로운 가치를 생산하고자 한다는 것입니다. 단지, 소프트웨어 개발은 개발자 역량만 훌륭하다고 되는 것이 아니며, 개발자간의 원활한 커뮤니케이션, 각 팀과의 원활한 커뮤니케이션, 더 나아가 조직과의 커뮤니케이션과도 연관 고리가 존재하게 됩니다.
콩 심은 곳엔 콩이 나고, 팥 심은 곳엔 팥이 나야 하지만, 실제 프로젝트에서는 콩 심은 곳에 팥이 나기도 합니다. 협업을 하다 보면 협업 자체가 어려운 것이 아니라, 사람을 대하는 것이 가장 어렵다는 것을 느낄 수 있을 것입니다. 그래서 애자일(Agile) 한 방법론이 최근 팀과 조직에서 관심의 대상이 되는 것과 같은 이치입니다. 애자일 방법론을 잘 하기 위해서는 사람과 인간성을 이해하고 신뢰를 쌓는 것이지만, 그렇게 애자일하게 너그러운 사람과 팀, 조직은 그리 흔하지 않습니다.
그렇다면 뭐가 문제일까요? 사람을 대하는 것이 어렵고, 고로 협업을 하는 것이 어렵고, 고로 전체 프로젝트를 수행하는게 어렵습니다. 개개인의 인격과 인간성을 존중하기엔 시간이 넉넉치 않을 뿐더러, 그들 간의 업무를 조율하는 것은 더 어려워지고, 점점 위태로운 프로젝트가 되기도 합니다. 물론 필자 또한 이런 문제의 발원지가 되기도 해보았고, 이것을 조율하는 입장도 되어 본 경험입니다.
그럼 이미 답은 나왔습니다. 바로 "강제성" 을 부여하는 것입니다. 강제성이라고 하면 오히려 비 애자일하다고 할 수 있겠지만, 바꾸어 말하면 "당신 하나 때문에~" 애자일을 하는 것이 아니라는 것입니다. 가장 표준적이면서도 쉬운 방법을 통해 목표의 방향성을 가지고 간다는 것이 더 중요할 수 있기 때문입니다.
어떻게 커뮤니케이션을 할 것인가?
사람과 사람, 팀과 팀, 조직과 조직, 기업과 기업, 이들 간의 커뮤니케이션은 매우 다양합니다. 메신저, 이메일, 그 밖에 다양한 방법이 존재합니다.
사람마다 선호하는 방법은 틀리겠지만, 개인적으로는 메신저야말로 가장 업무적으로 방해가 되는 커뮤니케이션 방법이라고 생각합니다. 언제나 급한 분들에게는 가장 좋은 커뮤니케이션 방법이 메신저가 될 수 도 있을 것입니다.
제가 가장 좋아하는 커뮤니케이션 방법은 이메일입니다. 제가 이메일을 열람하고 싶을 때 보고 업무를 처리하면 되니까요. 하지만 이메일은 기록되고 보관되기 때문에 가장 책임감을 발휘해야 하는 커뮤니케이션 방법이기도 합니다. 하지만 요즘 스마트폰의 열풍으로 직장이든 가정이든 이메일을 볼 수 밖에 없는 현실이 되었죠^^;
최근에는 SNS 와 같은 방법으로 커뮤니케이션을 하기도 합니다. 우리가 흔히 알고 있는 트위터(Twitter) 와 같은 Public SNS 도 존재하지만, 기업 내에서 사용할 수 있는 Private SNS 도 있습니다. 간단 명료한 메시지라는 강점으로 최근 유행하는 방식이기도 합니다.
Team Foundation Server 의 구성 요소를 통한 커뮤니케이션
Team Foundation Server(이하 TFS) 는 단독적으로 사용할 때 보다 여러 가지 구성 요소를 갖출 때 비로소 가장 효과적인 커뮤니케이션 방법을 제공해 줍니다.
최소한으로 TFS 는 SQL Server 를 필요로 하며, SQL Server 는 TFS 를 통해 소스 제어(Source Control), 리포팅(Reporting) 서비스를 제공해 줍니다. Team Foundation Server 를 사용하는 목적으로 SQL Server 라이선스를 일부 무료로 제공하기 때문에 가장 저렴한 비용으로 커뮤니케이션을 할 수 있는 방법입니다.
이를 이용하여 최소한으로 이행할 수 있는 여러 가지 기능이 있습니다.
소스 제어(Source Control)
소스 코드 브랜치(Branch)
리포팅 서비스 및 데이터 웨어하우스(Reporting Services and Data Warehouse)
일부 오피스(Office) 제품 연동
하지만 위의 방법으로는 조금 부족한 감이 있습니다. 마찬가지로 Team Foundation Server 를 사용하게 되면, SQL Server, Sharepoint Server 의 일부 라이선스를 무료로 제공하기 때문에 더욱 효과적인 커뮤니케이션 인프라를 구축할 수 있습니다. 특히 SharePoint 는 팀 포털과 문서 관리의 이점 뿐만 아니라, 팀 워크플로우를 개선할 수 있는 다양한 방법을 제공합니다. 특히 큰 규모에서는 의사 결정권이라는 막강한 권한이나 프로세스가 존재하게 되는데, SharePoint 는 이러한 워크플로우를 상당히 효과적으로 개선할 수 있는 솔루션이기도 합니다.
소스 제어(Source Control)
소스 코드 브랜치(Branch)
리포팅 서비스 및 데이터 웨어하우스(Reporting Services and Data Warehouse)
다양한 오피스(Office) 제품 연동
팀 포털, 문서 관리, 팀 프로세스 개선
최근 가상화(Virtualization) 를 기반으로 클라우드 서비스가 매우 큰 개발 및 비즈니스 영역으로 자리잡고 있습니다. 소프트웨어 가상화는 물론이고 우리가 흔히 알고 있는 하드웨어 가상화 등 이러한 서비스 가상화를 통해 이전에는 상상하기 힘들거나 환경을 구성하기 힘든 영역까지 모두 커버하고 있습니다. Microsoft 에서는 이것을 가리켜 Dynamic IT 라고 칭하고 있습니다.
그 중, System Center 솔루션은 매우 다양한 역할을 수행합니다. 가상화 인프라와 서버 모니터링을 위해 다양한 솔루션은 아래와 같습니다.
솔루션
설명
SCVMM
(System Center Virtual Machine Manager)
물리적인 서버 또는 가상화의 서버를 관리, 배포, 최적화하는 솔루션이다. Hyper-V 또는 VMWare 등 여러 가상화 플랫폼을 지원한다.
SCOM
(System Center Operation Manager)
데이터센터의 운영을 중앙 관리를 위한 솔루션이다. 분산되어 있는 서버의 상태, 성능 정보, 구성 또는 보안 상태를 감지한다. 윈도우 운영체제와 리눅스(Linux), 유닉스(Unix) 운영체제 의 리소스나 그 하위 구성요소를 모니터링 할 수 있다.
SCCM
(System Center Configuration Manager)
운영체제 배포, 보안 패치, 서버/데스크탑 정책, 모바일 정책 등 총체적인 서버 및 클라이언트의 구성을 관리하는 솔루션이다. 기업의 네트워크 내의 모든 컴퓨터를 대상으로 강제 업데이트, 필수 구성 요소 등을 정책적으로 강제화 할 수 있다.
SCVMM(System Center Virtual Machine Manager) 은 가상화를 통한 동적 서버 관리, 가상화를 통한 유지 관리 계획, 가상화를 통한 테스트 및 개발 환경 의 작업을 관리하고 단순화 위한 가상화 관리 솔루션입니다. 가상화 서버를 관리를 용이하게 하고, 물리적인 서버를 가상화로 쉽게 전환하거나 가상 호스트에 여러 개의 물리적 서버를 통합할 수 있습니다.
특히 이 솔루션은 ALM(Application Lifecycle Management) 솔루션 중 Team Foundation Server 2010 에서 테스트 가상화를 사용하기 위해 필요한 구성 요소이기도 합니다.
SCOM(System Center Operation Manager) 는 분산되어 있는 데이터 센터를 통합 관리를 하며 윈도우 운영체제 뿐만 아니라 다양한 리눅스, 유닉스 기반의 운영체제를 지원합니다. 이 솔루션을 이용하면 특정 장애나 서비스 성능, 가용성을 보장하기 위해 자동으로 조치를 취하도록 할 수 있습니다.
SCCM(System Center Configuration Manager) 는 네트워크 인프라에 존재하는 클라이언트 컴퓨터, 서버 컴퓨터 등의 구성을 중앙에서 관리합니다. 예를 들어, 일부 클라이언트 사용자의 컴퓨터는 윈도우의 업데이트를 꾸준히 사용하지 않는 경우가 있습니다. 이러한 경우 강제적으로 업데이트를 수행하도록 정책적으로 관리를 할 수 있습니다. 그 밖에 윈도우 방화벽 설정, 자동 업데이트 및 백신 프로그램 등을 정책적으로 설치되거나 구성하도록 강제화 할 수 있습니다.
현재 협업을 위한 기본적인 기반 환경은?
단지, 필자가 오늘 하고 싶은 이야기는 여러분들에게 여러 가지 솔루션이 이를 대체할 것이라는 암시를 주는 것이 아닙니다. 단지 협업은 혼자만의 노력으로는 불가능 한 것이며, 이것을 뒷받침해 줄 수 있는 도구가 있다는 것에 감사할 뿐입니다.
대부분의 우리나라 조직은 상하 수직적인 관계입니다. 일을 던져주고, 그것을 받고 일을 하는 수직적인 줄타기 방식은 작업의 결과를 매우 가시적이고 평가하기 쉬운 방법입니다. 그리고 이런 방식에 저 또한 매우 길들여져 있으며, 일을 수행하는 입장에서도 매우 수월합니다. 수행 결과를 보여주기도 쉽고, 처리하기도 쉽습니다.
다만 수평적인 조직(절대적인 수평은 없을 것이지만)에서는 오히려 상하 수직적인 방식과는 다릅니다. 항상 중간 과정에 서로의 동의와 협력이 필요하며, 그 성과 또한 개인의 성과가 아닌 우리의 성과가 될 테니까요.
하지만, 여러 조직과 기업이나 프로젝트에서 일을 해 본 경험으로, 절대적인 상하 수직적, 수평적인 조직은 없다는 것입니다. 그리고 필자 또한 어떤 것이 바람직한지 아직은 확신을 하기 어렵습니다. 다만, "그때 그때 잘~" 이라는 것밖에는 ^^
팀워크(Team Work) 란 팀이 무너지지 않고 존재할 수 있는 가장 큰 힘을 발휘합니다. 반대로 팀 워크가 수년간 같은 방식이고 개선되지 않고 제자리에 머물러 있다면 썩은 우물과도 같습니다. 왜냐하면 시대가 변함에 따라 개개인의 커뮤니케이션 방식은 바뀔 것이며, 점차적으로 개선되어 지지 않는다면 팀 워크가 아닌 커뮤니케이션 자체의 문제의 한계에 부딪히게 될 것입니다.
일단 오늘은 협업에 대해 썰을 풀어 보았습니다. 그리고 협업을 위한 많은 노하우를 여러분들에게 알려드리고 개선해 나가고자 합니다. 언제든지 불편한 내용이나 피드백을 주시면 참고하여 개선하고자 하도록 하겠습니다.
지난번 포스팅까지는 멀티터치를 좀 더 손쉽게 구현할 수 있도록 해주는 제스처(GESTURE)를 이용한 방법을 알아보았습니다. 기본적으로는 OS 자체에서 이미 한 번 가공하고 난 데이터를 WM_GESTURE라는 메세지를 전달해 줍니다. 이런 방식을 통해 프로그래머는 가공된 데이터를 바로 사용하기만 하면 된다는 장점도 가지지만, 좀 더 커스텀한 나만의 터치입력 제어처리를 하기에는 다소 제한적이라는 단점도 동시에 얻게 됩니다. 오늘은 이런 경우를 위해, OS의 처리를 아무 것도 거치치 않은 순수 터치입력 데이터인 WM_TOUCH메세지를 이용해 멀티터치 UX를 구현하는 방법을 알아보도록 하겠습니다.
그럼 일단 예제를 살펴보기 전에, WM_GESTOURE로 구현할 수 없는 멀티터치 UX의 예제란 어떤 게 있을지 한 번 이야기 해 보겠습니다. 위에 있는 이미지는 Windows7에 기본으로 포함되어있는 그림판 입니다. 제 PC에서 마우스 두 개를 꽂고, 가상 멀티터치 드라이브를 통해 마우스의 입력을 터치 입력으로 인식하게 변경한 다음, 그림판의 view 영역에 동시에 두 개의 브러시를 통해 그림을 그리고 있는 모습입니다. 멀티터치… 멀티터치니까 당연히 두 개의 panning 제스처 인식이 동시에 처리되는 게 맞겠죠. 제가 마우스가 하나 더 있다면 세 개도 동시에 드로잉 할 수 있을 겁니다. (손은 두 개지만… ㅡ,.ㅡ;..)
‘좋아, 나는 팀 블로그에서 제스처를 이용한 멀티터치 프로그래밍 방법을 익혔으니까 이걸 내가 직접 한 번 짜봐야지!’ 하고 마음을 먹어봅니다. 하지만… 어떻게 구현해야 할 지 막상 감이 잡히질 않는군요. panning 제스처니까 CWnd::OnGesturePan(CPoint ptFrom, CPoint ptTo) 함수를 상속받아서 구현하면 될까요? 근데 입력이 동시에 두 개가 들어오면 함수가 어떤 식으로 호출될까요?
제스처를 통한 구현방법을 사용하는 경우엔 먼저 입력된 한 개의 panning 제스처만 인식이 됩니다. 만약에 제스처를 통해 위에 올린 스크린샷과 같은 저런 터치를 입력하면, OS는 저 것을 두 개의 panning이 아닌 rotate 내지는 zoom 제스처로 번역하게 되겠지요. 그림판에 저렇게 두 개의 라인이 드로잉 되는 모습을 보고 있어서 그렇지, 실제로 저 입력 동작을 지난 번 예제인 사각박스 움직이기 샘플에 입력했다면 당연히 zoom 내지는 rotate의 효과를 기대하게 될 겁니다.
바로 이런 경우, WM_GESTURE가 아닌 WM_TOUCH 메세지를 사용하면 되겠습니다. 동시에 입력되는 두 개의 터치 데이터를 그대로 전달받아서 각각의 panning 제스처로 인식하도록 직접 처리하면 되겠지요. 그렇게 하려면 어떻게 해야 하는지 지금부터 함께 예제를 작성하면서 알아 보도록 하겠습니다.
Task 1 : MFC Application 프로젝트를 만들자.
WM_GESTURE 활용 예제와 유사하게 이번에도 프로젝트 생성부터 단계적으로 알아보도록 하겠습니다. MFC 응용 프로그램 마법사에서 MFC 표준 스타일의 SDI 타입을 지정해 줍니다. wizard의 주요한 설정 화면을 이번에도 스크린샷으로 대신하겠습니다. 지난번과 달리 이번엔 한글판 스크린샷을 찍었네요 ㅎㅎ
BYTE digitizerStatus = (BYTE) GetSystemMetrics(SM_DIGITIZER);
if ((digitizerStatus & (NID_READY | NID_MULTI_INPUT)) == 0)
{
AfxMessageBox(L"현재 터치 입력이 불가능한 상태입니다.");
return FALSE;
}
BYTE nInputs = (BYTE) GetSystemMetrics(SM_MAXIMUMTOUCHES);
CString str;
str.Format(L"현재 %d개의 터치를 동시 인식할 수 있습니다.", nInputs);
AfxMessageBox(str);
위에 있는 코드를 CTouchPadApp::InitInstance() 에 넣고 프로그램을 실행시켰을 때, 아래와 같은 안내 메세지가 나오는걸 확인해 주세요.
하드웨어가 터치를 인식할 수 있는 장치인지를 확인하고 난 다음엔 예제 프로그램의 view 영역이 WM_TOUCH 메세지를 받을 수 있게끔 등록해 주는 절차가 필요합니다. 그렇지 않으면 터치 입력이 들어왔을 때 예전과 똑같이 WM_GESTURE만 날아오게 될 테니까요. 터치 메시지를 받는 윈도우로 등록해 주기 위해서는 CWnd::RegisterTouchWIndow() 함수를 호출해 주면 됩니다. 이 처리를 CChildView의 OnCreate() 함수에서 해주기로 합시다.
Ctrl + Shift + X 키를 눌러서 MFC Class Wizard 창을 띄워줍니다. WM_CREATE 메세지를 처리하는 핸들러를 추가해주세요. 그리고 핸들러에 아래의 간단한 코드를 추가하면 끝입니다 :)
if (!RegisterTouchWindow())
{
ASSERT(FALSE);
}
CWnd::RegisterTouchWIndow() 함수를 호출해주면 윈도우를 터치 윈도우로 등록하게 됩니다. 함수의 인자가 default value 때문에 생략되었는데, 터치 윈도우 등록을 해제하고 싶은 경우도 RegisterTouchWIndow( FALSE ) 를 호출해서 처리합니다. 터치 윈도우로 등록되고 나면 더이상 WM_GESTURE 메세지는 발생되지 않으며, 아무 가공도 거치지 않은 저레벨의 순수 터치 입력 데이터를 전달해 주는 메세지인 WM_TOUCH가 발생하게 됩니다.
헌데 우리는 지금 Win32 프로젝트가 아니라 MFC 프로젝트를 보고 있지요 ㅎㅎ WM_TOUCH를 메시지 프로시저 함수에서 바로 얻어오자는 게 아닌 이상, WM_TOUCH 발생시 호출되는 함수를 알아봐야겠습니다. 우리는 CWnd::OnTouchInput() 함수를 이용하면 되겠군요. 하지만 이 함수는 MFC 클래스 마법사에서는 표시되지 않으니, 직접 손으로 선언과 구현부를 적어주어야 합니다. ChildView.h 파일과 ChildView.cpp에 각각 아래의 코드를 넣어주세요.
// ChildView.h 파일에 추가.
// Overrides
protected:
virtual BOOL OnTouchInput(CPoint pt, int nInputNumber, int nInputsCount, PTOUCHINPUT pInput);
// ChildView.cpp 파일에 추가.
BOOL CChildView::OnTouchInput(CPoint pt, int nInputNumber, int nInputsCount, PTOUCHINPUT pInput)
{
// TODO: Handle Tocuh input messages here
return FALSE;
}
자, 이제 low-level의 터치 데이터를 직접 받아 처리하기 위한 모든 준비가 끝이 났습니다. 이제 사용자가 프로그램의 view 영역에 터치 입력을 할 때마다 OnTouchInput(…) 함수가 호출될 겁니다. 본격적인 터치 데이터의 활용 방법은 다음 포스팅에서 알아보도록 하겠습니다 ㅎㅎ
Outro
이번 포스팅에서는 WM_TOUCH를 이용해 멀티터치 UX를 구현해야 하는 경우에 대한 설명, 윈도우를 터치 윈도우로 등록하는 방법, WM_TOUCH가 발생할 때마다 호출되는 CWnd의 멤버함수 등에 대해 알아보았습니다. WM_TOUCH의 프로그래밍 방법을 알아보기 위한 예제인 TouchPad라는 이름의 프로젝트를 생성부터 기본 설정까지 함께 알아보았고요. 다음 포스팅 에서는 예제를 완성시켜 나가면서, low-level 터치 데이터를 조작하는 코드를 함께 알아보도록 하겠습니다.
Asynchronous Agents Library
– message 전달 함수. 2 ( 수신 )
작성자: 임준환( mumbi at daum dot net )
Message 수신
Message 를 message block 에 전송할 수 있듯이, message block 으로부터 수신할 수도 있습니다. message 수신 함수에도 전송 함수와 마찬가지로 동기 함수인 receive() 와 비 동기 함수인 try_receive() 가 있습니다.
동기 함수 receive()
동기 함수인 receive() 는 message block 으로부터 수신이 완료될 때 수신된 message 를 반환합니다. 만약 message block 에 어떠한 message 도 없다면 receive() 는 message block 에 수신할 message 가 있을 때까지 기다립니다.
아래는 receive() 의 선언입니다.
template <
class _Type
>
_Type receive(
ISource<_Type> * _Src,
unsigned int _Timeout = COOPERATIVE_TIMEOUT_INFINITE
);
template <
class _Type
>
_Type receive(
ISource<_Type> * _Src,
filter_method const& _Filter_proc,
unsigned int _Timeout = COOPERATIVE_TIMEOUT_INFINITE
);
template <
class _Type
>
_Type receive(
ISource<_Type> &_Src,
unsigned int _Timeout = COOPERATIVE_TIMEOUT_INFINITE
);
template <
class _Type
>
_Type receive(
ISource<_Type> &_Src,
filter_method const& _Filter_proc,
unsigned int _Timeout = COOPERATIVE_TIMEOUT_INFINITE
);
[ 코드1. receive() 의 선언 ]
템플릿 매개변수인 _Type 은 message 의 자료 형입니다.
함수 매개변수 중 _Src 는 message block 의 인터페이스 중 하나인 ISource 를 상속한 message block 객체이며, 이 객체로부터 message 를 수신합니다.
함수 매개변수 중 _Timeout 은 최대 대기 시간입니다. 이것은 receive() 가 동기 함수이기 때문에 영원히 기다릴 상황을 대비하는 방법입니다. 이 매개변수를 지정했을 때, 최대 대기 시간을 초과하였을 경우, agent::wait()( Asynchronous Agents Library – agent. 2 ( 기능 ) 참고 ) 와 마찬가지로 operation_timed_out 예외를 발생합니다. 그러므로 이 매개변수를 지정 시 반드시 해당 예외를 처리해주어야 합니다. 기본 인자로 COOPERATIVE_TIME_INFINITE 가 지정되어 있으며, 무한히 기다리는 것을 의미합니다.
함수 매개변수 중 _Filter_proc 는 message 를 거부할 수 있는 필터입니다. message block 생성자로 지정할 수 있는 필터와 마찬가지로 std::tr1::function<bool(_Type const&)> 입니다.
템플릿 매개변수인 _Type 은 receive() 와 마찬가지로 message 의 자료 형입니다.
함수 매개변수 중 _Src 도 receive() 와 마찬가지로 message block 의 인터페이스 중 하나인 ISource 를 상속한 message block 객체이며, 이 객체로부터 message 를 수신합니다.
함수 매개변수 중 _value 는 수신한 message 를 저장할 변수의 참조입니다. 수신이 성공하면 message 는 이 참조가 가리키는 변수에 저장됩니다.
함수 매개변수 중 _Filter_proc 는 receive() 와 마찬가지로 message 를 거부할 수 있는 필터입니다.
try_receive() 는 수신의 완료를 기다리지 않기 때문에 수신을 시도했을 때( try_receive() 를 호출했을 때 ) message block 에 어떠한 message 도 없다면 false 를 반환해 알려줍니다. message 가 있다면 true 를 반환합니다.
만약, 수신 시도를 하자마자 시도한 컨텍스트가 계속 진행되기를 원한다면 receive() 에 _Timeout 매개변수에 0 을 지정하기 보다는 try_receive() 를 사용하는게 바람직합니다.
동기 함수인 receive() 와는 달리 비 동기 함수인 try_receive() 는 수신할 message 가 없을 경우, 기다리지 않고 false 를 반환합니다.
수신할 message 가 있든 없든 바로 반환해야 하는 경우라면 receive() 의 매개변수인 최대 대기 시간을 0 으로 지정하는 것보다는 try_receive() 를 권장합니다.
receive() 의 최대 대기 시간은 예외 메커니즘을 사용하므로 try_receive() 에 비해 오버헤드가 있을 수 있습니다.
[ 그림4. try_receive() 의 수신할 message 가 없는 경우 예제 실행 결과 ]
Message 필터
지난 글에서 message block 에 필터를 지정할 수 있다고 언급했습니다. message block 에 지정되는 필터는 message block 에 전송 시에 적용됩니다.
마찬가지로 수신 함수들에도 필터를 지정할 수 있습니다. message block 으로부터 수신 시에 적용됩니다.
동기 함수인 receive() 는 수신할 message 가 필터에 의해 수락될 때까지 대기합니다. 즉, 수신할 message 가 필터에 의해 거부된다면 message block 에 message 가 없을 때와 같습니다.
비 동기 함수인 try_receive() 또한 message block 에 message 가 없을 때와 마찬가지로 false 를 반환합니다.
다시 말해, message block 에 message 가 없는 경우에도 필터에 의해 거부된다는 말과 같습니다.
그럼, 필터를 이용한 수신 함수에 대한 예제를 살펴보겠습니다.
예제
#include <iostream>
#include <vector>
#include <iterator>
#include <functional>
#include <agents.h>
#include <ppl.h>
using namespace std;
using namespace std::tr1;
using namespace Concurrency;
class number_collector
: public agent
{
public:
number_collector( ISource< int >& source, vector< int >& result, function< bool ( int ) > filter )
: source( source )
, result( result )
, filter( filter ) { }
protected:
void run()
{
while( true )
{
int number = receive( this->source, this->filter );
if( 0 == number )
break;
this->result.push_back( number );
}
this->done();
}
private:
ISource< int >& source;
vector< int >& result;
function< bool ( int ) > filter;
};
int main()
{
// message block
unbounded_buffer< int > message_block;
// send number 1 ~ 10.
parallel_for( 1, 11, [&]( int number )
{
send( message_block, number );
} );
// send stop signal.
send( message_block, 0 ); // for even.
send( message_block, 0 ); // for odd.
vector< int > even_number_array, odd_number_array;
number_collector even_number_collector( message_block, even_number_array, []( int number ) -> bool
{
return 0 == number % 2;
} );
number_collector odd_number_collector( message_block, odd_number_array, []( int number ) -> bool
{
if( 0 == number )
return true;
return 0 != number % 2;
} );
even_number_collector.start();
odd_number_collector.start();
// wait for all agents.
agent* number_collectors[2] = { &even_number_collector, &odd_number_collector };
agent::wait_for_all( 2, number_collectors );
// print
wcout << L"odd numbers: ";
copy( odd_number_array.begin(), odd_number_array.end(), ostream_iterator< int, wchar_t >( wcout, L" " ) );
wcout << endl << L"even numbers: ";
copy( even_number_array.begin(), even_number_array.end(), ostream_iterator< int, wchar_t >( wcout, L" " ) );
wcout << endl;
}
[ 코드7. 필터를 이용한 숫자 고르기 예제 ]
우선 message block 에 1 ~ 10 의 정수를 전송합니다. parallel_for() 를 사용하였는데 이 함수는 Concurrency Runtime 위에서 AAL 과 작동하는 돌아가는 Parallel Patterns Library( 이하, PPL ) 에서 제공하는 함수입니다. PPL 에 대한 자세항 사항은 visual studio 팀 블로그에서 확인하실 수 있습니다.
parallel_for() 는 반복될 내용을 병렬로 처리하기 때문에 성능에 도움을 줍니다. 그러나 반복되는 순서를 보장하지 않습니다.
그래서 1 ~ 10 의 정수가 전송되는 순서는 알 수 없습니다. 하지만 1 ~ 10 의 정수를 모두 전송한 뒤, 0을 보내서 마지막 message 라는 것을 알려주었습니다. 두 번 보낸 0 중 하나는 짝수를 수신하는 agent 를 위한 것이고, 하나는 홀수를 수신하는 agent 를 위한 것입니다.
사실, 이런 처리 로직을 구성할 때에는 상태 변화 알림에 유용한 다른 message block 을 사용하는 것이 좋지만 아직 message block 에 대해서 설명하지 않았기 때문에 혼란을 줄이기 위해 간단한 unbounded_buffer 하나만으로 처리하였습니다.
위 코드에 정의된 agent 인 number_collector 는 message block 으로부터 필터에 의해 필터링된 message 를 컨테이너에 저장합니다.
동기 함수인 receive() 를 사용했기 때문에 원하는 message 가 올 때까지 기다립니다. 이로 인해 필요한 만큼의 최소의 반복을 하여 오버헤드가 줄어 듭니다.
만약 비 동기 함수인 try_receive() 를 사용했다면 쓸모 없는 반복 오버헤드를 발생시킬 것입니다. 이 예제의 경우에는 동기 함수인 receive() 가 적합합니다.
정의된 agent 를 짝수용과 홀수용을 선언하고 start() 를 사용하여 작업을 시작합니다. 그리고 wait_for_all() 을 사용하여 두 agent 가 모두 끝날 때까지 기다린 후, 모든 작업이 종료되면 화면에 수집한 정수들을 출력합니다.
위 예제 코드는 Visual studio 2008 부터 지원하는 tr1 의 function 과 visual studio 2010 부터 지원하는 C++0x 의 람다를 사용하였습니다. Concurrency Runtime 은 tr1, C++0x 등의 visual studio 2010 의 새로운 feature 들을 사용하여 구현되었기 때문에 이것들에 대해 알아두는 것이 좋습니다.
[ 그림5. 필터를 이용한 숫자 고르기 예제 실행 결과 ]
마치는 글
이 글에서는 message 전달 함수 중 수신 함수인 receive() 와 try_receive() 에 대해서 알아보았습니다.
receive() 와 try_receive() 는 사용해야 할 상황이 분명히 다르니 상황에 따라 사용에 유의해야 합니다.
다음 글에서는 message 가 저장되는 message block 에 대해서 알아보도록 하겠습니다.










![[ 그림1. agent 와 unbounded_buffer 를 이용한 메시지 펌프 간략 구현 결과 ]](https://t1.daumcdn.net/cfile/tistory/187E9A134C4E83D057)



















 Stroke.cpp
Stroke.cpp































![[ 그림2. receive() 의 수신할 message 가 없는 경우 예제 실행 결과 ]](https://t1.daumcdn.net/cfile/tistory/146D01264C257FD164)
![[ 그림3. try_receive() 의 수신할 message 가 있는 경우 예제 실행 결과 ]](https://t1.daumcdn.net/cfile/tistory/17099B284C25802921)
![[ 그림5. 필터를 이용한 숫자 고르기 예제 실행 결과 ]](https://t1.daumcdn.net/cfile/tistory/157758264C2580A420)
